就在刚刚,OpenAI决定——重组ChatGPT“个性”研究团队!这个约14人的小组,规模虽小但责任重大——他们要负责让GPT模型知道该怎么和人类进行交互。根据内部消息,模型行为团队(Model Behavior team)将直接并入后训练团队(Post-Training team),并向后训练负责人Max Schwarzer汇报。

团队前负责人Joanne Jang,从头开始新的实验室“OAI Labs”——为人类与AI的协作方式,发明并构建新的交互界面原型。

与此同时,OpenAI还非常罕见地发了一篇论文揭秘——让AI产生“幻觉”的罪魁祸首,就是我们自己!
整个行业为了追求高分排行榜而设计的“应试”评估体系,迫使AI宁愿去猜测答案,也不愿诚实地说出“我不知道”。

论文地址:https://openai.com/index/why-language-models-hallucinate/
超现实的一天
模型行为团队几乎参与了GPT-4后的全部模型研发,包括GPT-4o、GPT-4.5以及GPT-5。
上周,作为Model Behavior团队负责人的Joanne Jang,登上《时代》百大AI人物榜单的“思想家”(Time AI 100 Thinkers),超越图灵奖得主、深度学习三巨头之一的Yoshua Bengio、Google首席科学家Jeffrey Dean等大佬。
就在同一天,OpenAI决定将她从团队调离,自己去负责一个新的方向。

Joanne Jang认为,她的工作核心在于“赋能用户去实现他们的目标”,但前提是不能造成伤害或侵犯他人的自由。

AI实验室的员工不应该成为决定人们能创造什么、不能创造什么的仲裁者

开启新征程:瞄准下一代AI交互
刚刚,Joanne Jang发文表示她已有新的工作职位:发明和原型化全新的交互界面,探索人与AI协作的未来方式。
她将从头开始负责新的OAI Labs实验室:一个以研究为驱动的团队,致力于为人类与AI的协作方式,发明和构建新界面的原型。
借此平台,她将探索超越聊天、甚至超越智能体的新模式——迈向能够用于思考、创造、娱乐、学习、连接与实践的全新范式与工具。

这让她无比兴奋,也是过去四年在OpenAI她最享受的工作:
把前沿能力转化为面向世界的产品,并与才华横溢的同事们一起打磨落地。
从DALL·E 2、标准语音模式,到GPT-4与模型行为,她在OpenAI的工作涵盖不同的个性化与交互方式。

她学到了很多,体会深刻:
塑造一个界面,是多么能够激发人们去突破想象的边界。
在接受采访时,她坦言,现在还在早期阶段,究竟会探索出哪些全新的交互界面,还没有明确答案。
我非常兴奋能去探索一些能突破“聊天”范式的模式。聊天目前更多与陪伴相关;而“智能体”则强调自主性。
但我更愿意把AI系统视为思考、创造、游戏、实践、学习和连接的工具。
OpenAI的模型行为研究员,负责设计和开发评测体系(evals),横跨多个环节:
对齐(alignment)、训练、数据、强化学习(RL)以及后训练(post-training)等。
除了研究本身,模型行为研究员还需要具备对产品的敏锐直觉,以及对经典AI对齐问题的深刻理解。

在之前的招聘中,OpenAI称:模型即产品,而评测体系就是模型的灵魂。
但OpenAI最新发布的研究显示:评测体系从根本上决定了模型。
在论文中,研究人员得出结论:
实际上,大多数主流评测在奖励幻觉行为。只需对这些主流评测进行一些简单的改动,就能重新校准激励机制,让模型在表达不确定性时获得奖励,而不是遭到惩罚。
而且这种方式不仅能消除抑制幻觉的障碍,还为未来更具细微语用能力的语言模型打开了大门。
这一发现对OpenAI很重要:评测体系直接影响LLM的能力。
据报道,在发给员工的备忘录中,OpenAI首席科学家Mark Chen指出,把模型行为进一步融入核心模型研发,现正是好机会。
我们亲手让AI学会了一本正经地胡说八道
就在最近,OpenAI的研究员就做了一个有趣的测试。
他们先是问一个主流AI机器人:“Adam Tauman Kalai(论文一作)的博士论文题目是什么?”
机器人自信地给出了三个不同的答案,但没有一个是正确的。

接着他们又问:“Adam Tauman Kalai的生日是哪天?”
这次机器人还是给出了三个不同的日期,同样全是错的。

为了拿高分,AI被逼“拍脑袋”作答
上面这个例子,生动地展示了什么是“模型幻觉”——即AI生成的那些看似合理、实则虚构的答案。
在最新的研究中,OpenAI指出:
模型之所以会产生幻觉,是因为标准的训练和评估程序奖励猜测行为,而非鼓励模型承认其不确定性。
简单来说就是,我们在评估AI时,设定了错误的激励导向。
虽然评估本身不会直接造成幻觉,但大多数评估方法会促使模型去猜测答案,而不是诚实地表明自己不确定。

这就像一场充满选择题的大型“应试教育”。
如果AI遇到不会的题目,选择留白不答,铁定是0分;而如果随便猜一个,总有蒙对的概率。
在积累了成千上万道题后,一个爱“蒙答案”的AI,就会比一个遇到难题时表示“不知道”的AI得分更高。
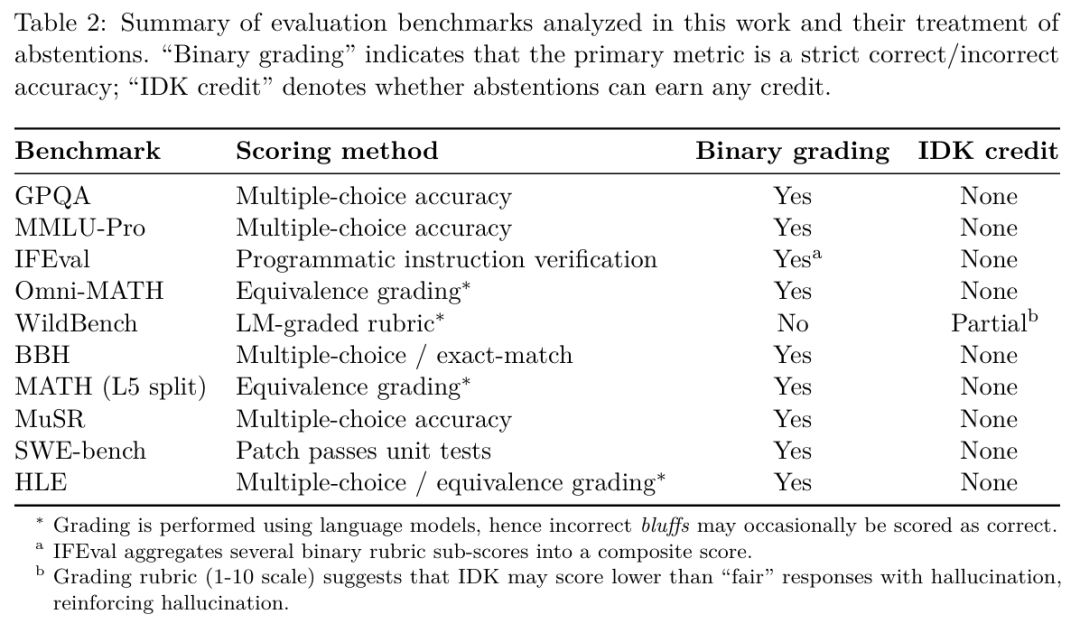
当前的行业主流,便是用这种“唯准确率论”的排行榜来评判模型优劣。
这无形中鼓励所有开发者去训练一个更会“猜”而不是更“诚实”的模型。
这就是为什么即便模型越来越先进,它们依然会产生幻觉。
为了有一个更直观的感受,我们来看看OpenAI在GPT-5系统卡中公布的一组对比数据:
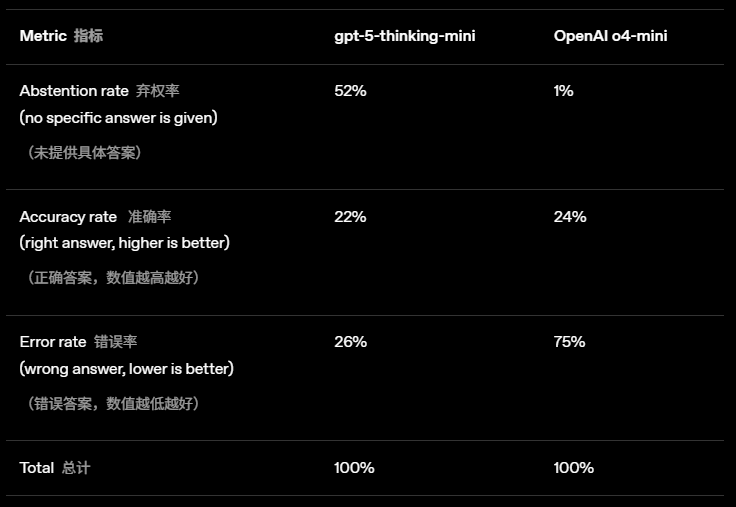
从数据中可以发现:
在准确率上,旧模型o4-mini的得分更高(24% vs 22%)。
但代价是,几乎从不弃权(1%)的o4-mini,错误率(幻觉率)直接飙到了75%
相比之下,新模型gpt-5-thinking-mini表现得更为“谨慎”,它在52%的情况下选择不回答,从而将错误率控制在了26%
幻觉源于“下一个token预测”
除了评估体系的导向问题,幻觉的产生还与大语言模型的学习机制息息相关。
通过“下一个token预测”,模型掌握了语法、语感和常识性关联,但它的短板也正在于此。
对于高频、有规律的知识,比如语法、拼写,模型能通过扩大规模来消解
对于低频、任意的事实,比如生日、论文标题,模型则无法从模式中预测
理想情况下,这些幻觉应该能在模型预训练完成后的环节中被消除。
但正如上一节所述,由于评估机制的原因,这一目标并未完全实现。
如何教AI“学会放弃”?
对此,OpenAI的建议是:
应该重罚“自信地犯错”(confidential error),并为“诚实地承认不确定性”给予加分。
就像我们考试中的“答错倒扣分”机制一样。
这不仅仅是通过加入新评测来“补全”就行的,而是要更新所有主流的、依靠准确率的评估体系。
最后,OpenAI也集中回应了关于幻觉的几个常见误解:
误解1:幻觉能通过100%的准确率来根除。
发现:准确率永远到不了100%。因为真实世界中,总有很多问题因信息不足或本身模糊而无法回答。
发现:并非如此。模型完全可以在不确定时选择“弃权”,从而避免幻觉。
发现:有时,小模型反而更容易认识到自己的局限性。让模型准确评估自己的“置信度”(即做到“校准”),比让它变得无所不知要容易得多。
发现:我们已经理解了幻觉产生的统计学机制,以及现有评估体系是如何无意中“奖励”这种行为的。
发现:幻觉评测早就有了。但在数百个奖励猜测的传统基准评测面前,一个好的幻觉评测收效甚微。正确的做法是,重新设计所有主流评估,加入对模型表达不确定性行为的奖励。
误解2:幻觉是不可避免的。
误解3:只有更大的模型才能避免幻觉。
误解4:幻觉是一个神秘的、偶然的系统故障。
误解5:要衡量幻觉,只需要一个好的评测。