台积电是晶圆代工领域当之无愧的龙头,也是芯片行业不可或缺的重要角色。他们是怎样再过去几十年里成长到今天的?我们来复盘一下台积电的崛起之路。
第一阶段——启动
首先回顾一下历史:该公司成立于1986年,张忠谋担任董事长,此前不久,他移居台湾,担任工业技术研究院(ITRI)院长。公司启动资金为4800万美元,其中行政院发展基金(48.3%)、飞利浦(27.5%),其余资金来自其他受到政府施压的台湾公司。1988年,该公司又进行了两轮融资,分别为2900万美元和2.05亿美元,总融资额达到2.82亿美元。
生产于次年(1987年)开始,最初是在租用的工研院6英寸晶圆厂进行,采用工研院的2微米和3.5微米技术。随后,飞利浦很快为其定制了3.0微米技术,这可能是飞利浦首个真正意义上的量产工艺。
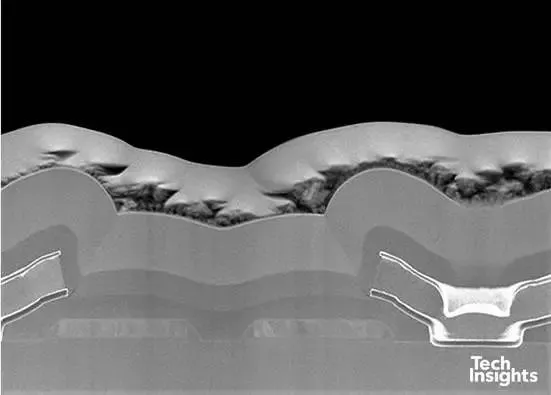
图 1-TSMC-3-µm-a
如您所见,这是一种单多晶硅、单金属工艺;我们标注了图片,因为您可能得年过60才能认出这项技术!1988年,1.5微米技术迅速跟进。
他们的网站上的这个图很好地显示了流程开发的快速顺序;
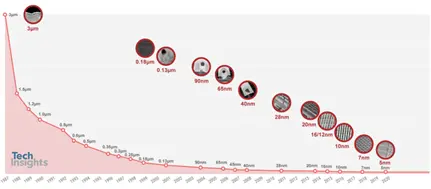
图 2 工艺技术节点
台积电于1994年上市,彼时已发展到0.6微米三金属逻辑工艺,以及双多晶硅、双金属混合信号工艺和1.0微米BiCMOS工艺。当时,台积电的晶圆厂IIA和IIB仍在运营,8英寸晶圆厂III也已投入运营。1990年至1994年间,台积电晶圆出货量达250万片,销售额从22亿新台币增长至193亿新台币,可见其代工模式正蓬勃发展。

图3-Altera 0.6 µm EPLD 的横截面
上图所示的 Altera EPLD 只是 0.6 µm 工艺的双金属版本,但我们可以看到,平坦化(至少是平坦化的程度)是通过流动玻璃(磷硅酸盐玻璃或硼磷硅酸盐玻璃,即 PSG 或 BPSG)、旋涂玻璃 (SOG)、氧化物沉积和回蚀工艺的组合实现的。在三层金属层之前,这种工艺效果良好,但超过三层金属层后,凹凸不平就变得过于严重,铝的阶梯覆盖根本无法应对。ICE 评估显示,触点中的金属厚度减薄了高达 75%。(ICE——集成电路工程公司,是一家总部位于凤凰城的公司,于 2001 年被 Chipworks 收购。我们不得不追溯到很久以前才找到其中一些记录!)
我们还发展到在栅极上使用硅化钨,但在源极/漏极上还没有,而且 locos 仍然是器件隔离的主要方法。
第二阶段——扩张与追赶
1995年,8英寸晶圆厂三号(Fab III)正式启用,并引入了钨塞。尽管IBM早在几年前就开发出了CMP(化学机械平坦化)技术,但钨塞的形成仍是通过沉积和回蚀工艺。钨塞的使用改善了平坦化工艺,并使得更多金属得以应用:
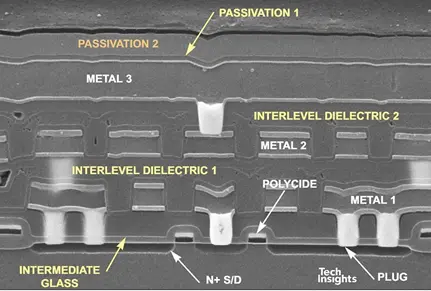
图 4-Altera 0.5 µm EPLD 的横截面
到了 0.35 µm(1997 年),台积电已采用 CMP,并在源极/漏极上使用硅化钛,尽管钨仍留在栅极上。

图 5-Pericom 0.35 µm PCI 桥的横截面
同样在1997年,台积电开始采用“半节点”工艺,推出了0.3微米工艺,并开设了晶圆厂V。第二年,我们看到了第一款0.25微米产品——正如我们所见,我们在这一部分全面实施了六种金属的CMP、完全自对准的硅化钛(Ti salicide),并引入了浅沟槽隔离(STI)。
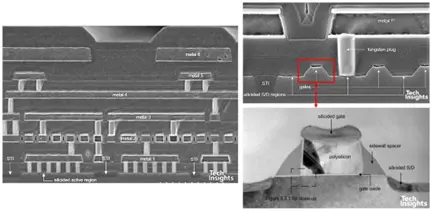
图 6:飞利浦 0.25 µm 图形处理器的横截面
业务方面,1998年,公司营收达新台币500亿元,出货120万片8寸当量晶圆,当时正值半导体经济衰退的一年,位于俄勒冈州的Wafertech晶圆厂开始出货晶圆。
最近,台积电前研发副总裁蒋尚义向计算机历史博物馆贡献了他的口述历史,他表示,他们的0.25微米工艺使用氟硅酸盐玻璃(FSG)作为低k介电材料。他还表示,推出这个节点极其困难,但他们还是按计划完成了。
1998 年也开始生产 0.22 µm 节点;正如预期的那样,它看起来与 0.25 µm 代非常相似,具有更紧密的金属间距,但晶体管结构发生了变化:
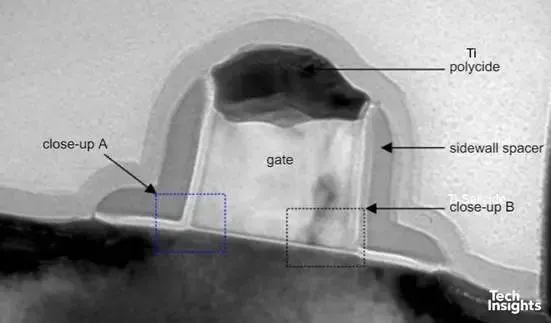
图 7:Altera 0.22 µm FPGA 晶体管的横截面
当时仍在使用钛硅硅化物,但现在我们使用的是L形侧壁间隔层,而不是三角形。栅极长度为0.16微米,因此我们现在处于一个节点名称开始变得毫无意义的时代——当栅极长度降至0.25微米时,它仍然是衡量制造代数的一个相当可靠的指标。
2000 年,在 0.18 µm(180 nm)处,我们注意到后端发生了变化,并在电介质堆栈中识别出了 FSG。(FSG 的介电常数约为 3.6,而 SiO2 的介电常数约为 4.0。)同年,晶圆厂 VI 也正式投产,该厂内部也拥有一条 300 毫米试产线。
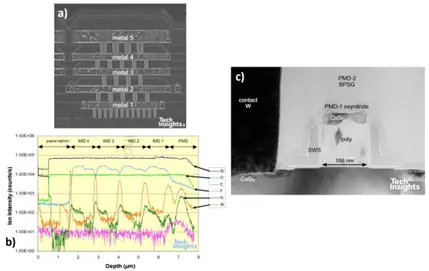
图 8:180 nm Lucent DSP a) 金属/电介质堆栈的横截面 b) 电介质堆栈的 SIMS 分析 c) 晶体管的横截面
晶体管结构中仍然保留了 L 形隔离层,但已转换为钴硅化物——栅极长度约为 130 纳米!上图所示的朗讯器件采用五层金属堆叠,但我们也分析了七层金属的器件。
千禧年是台积电的繁荣之年,销售额较 1999 年增长 127%,1992 年至 2000 年的年复合增长率达到 50%。
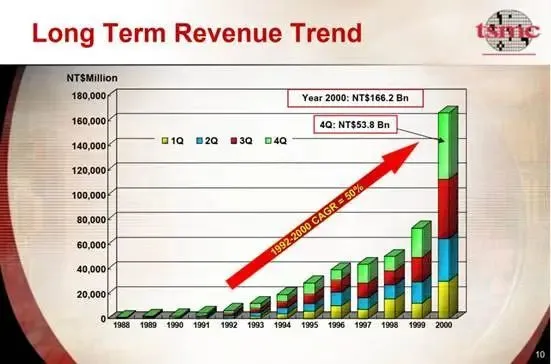
图 9-台积电-1992-2000
同年,150纳米工艺也正式推出,延续了半节点的模式。与此同时,研发部门正在开发130纳米(铜)工艺,并搭建300毫米制程,而位于新竹的300毫米晶圆厂12号和位于台南的300毫米晶圆厂14号正在建设中。
我们回顾一下1998年,当时0.25微米工艺刚刚推出。蒋尚义(台积电前研发副总裁)曾口述过一段往事:他1997年加入台积电时,台积电的论文甚至无法在IEDM或VLSI Symposia等会议上被接受。然而,到了1996年,代工模式得到了认可,F.C. Tseng(运营高级副总裁)在当年的IEDM大会上发表了全体会议报告。我们在1998年的VLSI大会上找到了台积电0.25微米工艺的详细介绍。
0.18µm(180nm)工艺在VLSI 99会议上进行了展示,有趣的是,会议中提到了使用旋涂低k电介质(氢倍半硅氧烷(HSQ))进行平坦化。Shang-Yi Chiang讲述了如下故事:“我们测试了它,一切都很顺利。所以我们用HSQ来替代FSG(氟硅酸盐玻璃)。效果很好……在研发阶段,我们必须进行一些可靠性鉴定。它在投产时通过了所有标准。但当产量很大时,我们开始遇到可靠性问题。我们在最后一刻才发现,当时我们已经开始投产了。当时正值圣诞节前后,我们立即尝试重新启用FSG,所以我们又日以继夜地工作,圣诞节不休息,新年不休息,中国新年也不休息。一路走来,在巨大的压力下,我们终于搞定了,产品出来了,虽然已经晚了,但效果很好。”
所以,这是一个很好的例子,说明当量产开始时,表面上的研发成功可能会遭遇挫折。同样地,IBM 也遇到了 SiLK 低 k 旋涂材料的问题,不得不回归 CVD 工艺。
第三阶段——
绘制水平,甚至(短暂地)领先
可以说,在180纳米节点上,台积电与其他领先制造商旗鼓相当,在尺寸方面可能落后几个月,但在FSG的使用方面略胜一筹。IBM和英特尔在1998-1999年推出了各自的180纳米工艺,但我们没有FSG使用记录。他们还在2000年从台南的Fab 6 12英寸试验生产线交付了300毫米客户晶圆。
150 纳米节点本质上是 180 纳米的缩小,具有七种金属和 FSG 电介质。

图 10:150 纳米 NVIDIA GPU 的横截面
2001年是集成电路市场历史上最糟糕的一年,下滑了32%。尽管如此,到第四季度,150纳米产品仍占据了销售额的21%,Fab 12也开始生产300毫米晶圆,尽管整体晶圆出货量有所下降。令人惊讶的是,即使在经济低迷时期,300毫米晶圆在2001年也占到了硅片总出货量的4%。
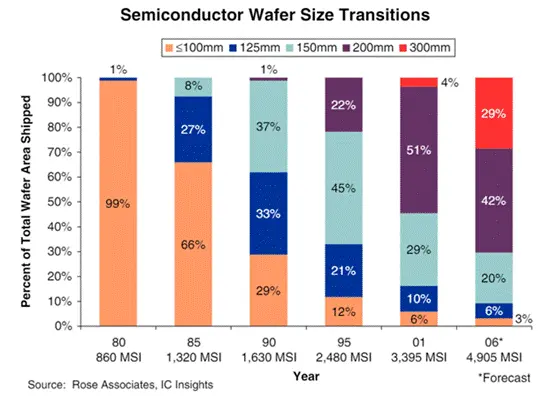
图11:半导体晶圆尺寸转变
2002年标志着工研院一厂租约的结束和退役,以及130纳米一代的批量推出,在第四季度产生了8%的销售额。
后端金属/电介质堆栈的RC延迟持续推动了对铜金属化和低k电介质的需求。IBM已在180纳米工艺中引入了铜,随着尺寸的不断缩小,显然,业内其他公司也必须跟进。
在150纳米和130纳米工艺节点,台积电在最初一两年引入了铜金属化技术,并以FSG作为后端电介质。该堆叠采用单大马士革铜作为金属1层,并搭配钨插头(如果铜渗透到衬底中,可能会缩短载流子寿命),上方的金属化层则采用双大马士革工艺。

图 12:130 纳米 Altera PLD 的横截面(200 毫米晶圆)
2003年4月,他们发布了采用应用材料公司Black Diamond技术的130纳米真低k电介质版本。“真低k”指的是k值为3.0或更低的电介质;据称Black Diamond的k值约为2.8。
最初,两家公司都采用 200 毫米晶圆制造,但随着铜工艺的成熟以及 300 毫米晶圆的量产,台积电成为第一家批量出货采用铜和低 k 电介质产品的公司,其中一些产品甚至采用 300 毫米晶圆。现在看来,这让他们领先于英特尔或 IBM 等其他代工厂和 IDM。
我们看到的第一款产品是 ATI 图形芯片,但直到 2003 年底才出现。

图 13:采用低 k 电介质的 130 纳米 ATI 图形处理器的横截面(200 毫米晶圆)
和往常一样,台积电在转向90纳米之前会提供一个过渡的110纳米节点,通常比130纳米节点缩小10%。但就NVIDIA的这个例子而言,它的成本似乎也降低了,因为它没有采用低k材料(这对于GPU来说有点令人惊讶!)。因此,沟槽和过孔的蚀刻明显比ATI的部件更精确。

图14:110纳米NVIDIA图形处理器(300毫米晶圆)的横截面
2004年是90纳米制程的元年,业界最终将其制程以纳米而非微米命名。这一年也是CMOS技术开创性的一年;登纳德缩放(Dennard scaling,同时减小栅极长度、栅极氧化层厚度和驱动电压)最终达到极限,因为栅极氧化层变得非常薄(约1.0-1.2纳米),载流子可以穿过它,从而显著增加了漏电流和功率损耗。
在130纳米工艺上,英特尔略微放慢了速度,没有使用低k值,并且姗姗来迟地转向了铜金属,但凭借着引入应变硅来提高载流子迁移率以及低k值,英特尔无疑占据了技术领先地位。他们在这方面并非独树一帜,其他公司也应用了迁移率增强技术;IBM、AMD和富士通也使用了拉伸氮化物。富士通和德州仪器采用了晶圆旋转技术,但只有英特尔使用了嵌入式SiGe源极/漏极技术来增强PMOS。
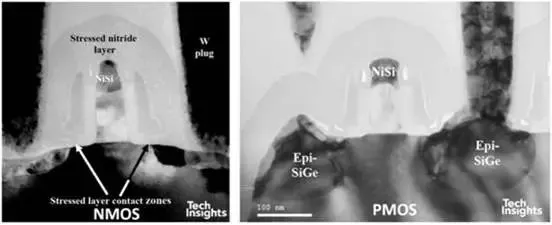
图 15:英特尔 90 纳米晶体管的应力机制
第四阶段——
300毫米,巩固和统治的开始
台积电的90纳米工艺是其首次在300毫米晶圆上完全量产的工艺,并宣称这是“全球首个实现全面量产的12英寸、低k、90纳米工艺”,当年就被30多家客户采用。
Chipworks 分析的产品是 Altera Stratix™-II FPGA。这是一款 10 层金属(9 层铜 + 1 层铝),在 M1 至 M6 层采用低 k 值。其晶体管结构并非直接从 130 纳米节点缩小而来;而是经过修改,改变了侧壁隔离结构,使其不再是前几代工艺中典型的 L 形隔离层。与英特尔的结构相比,氮化物覆盖层似乎太薄,无法用作应力层来增强迁移率。
台积电 90 纳米工艺的另一个主要特点是其向第二代低 k 电介质工艺的演变——沟槽和通孔蚀刻明显比 130 纳米节点更干净,并且覆盖层已变为 SiCO(而不是 SiCN)成分。

图 16:90 纳米 Altera Stratix FPGA 和 55 纳米栅极长度的横截面
上市十年后,台积电已拥有两座12英寸晶圆厂、五座8英寸晶圆厂、一座6英寸晶圆厂,以及两家全资子公司——美国WaferTech和中国台积电(上海)有限公司,以及一家合资晶圆厂——新加坡SSMC。台积电及其关联公司合计年装机产能为480万片8英寸晶圆当量。
在此背景下,企业研发部门正在稳步推进新型晶体管和工艺技术,例如SOI、finFET、MRAM、高k栅极电介质、金属栅极、应变硅,甚至纳米线。提到finFET,我们感到很惊讶,直到我们想起胡正铭曾于2001年至2004年担任台积电首席技术官(胡正明于1999年发表了第一篇finFET论文)。
他们也是首批与 ASML 和尼康合作研发浸没式光刻技术的公司之一,并于 2004 年获得了第一台 ASML 系统,同年宣布推出功能性 90 纳米测试芯片,并于 2006 年初在 12 英寸晶圆上实现了接近生产水平的0.014 /cm2 缺陷密度。
从早期开始,台积电就提供了基础逻辑工艺的变体,例如混合信号、嵌入式存储器、非易失性存储器和高压技术,到 21 世纪初,台积电已将它们战略化为两个“平台”——先进技术和主流技术。
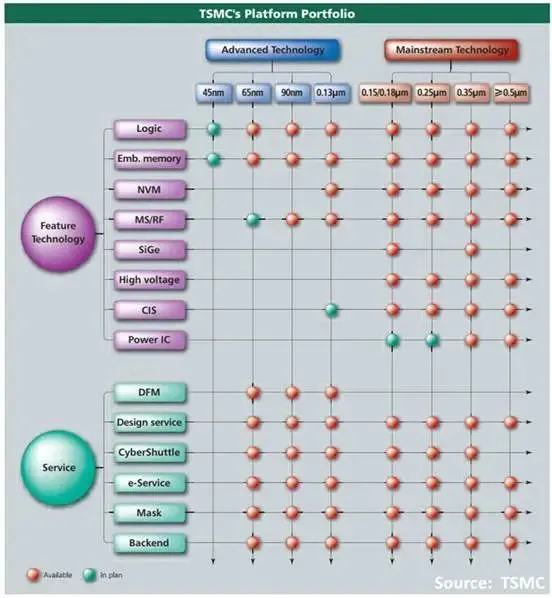
图17:台积电平台组合
我们没有时间或篇幅去详细讨论这些其他“主流”产品,但值得注意的是,在 6 英寸和 8 英寸晶圆上生产的 150 纳米及更大尺寸的产品占 2006 年销售额的 50%。
2006年初,80纳米半节点技术问世,这通常是一种90纳米工艺的光刻缩减。这些半节点技术可能难以识别,因为它们的结构与之前的全节点技术相似,但通过仔细比较金属间距,可以发现它们属于此类器件。
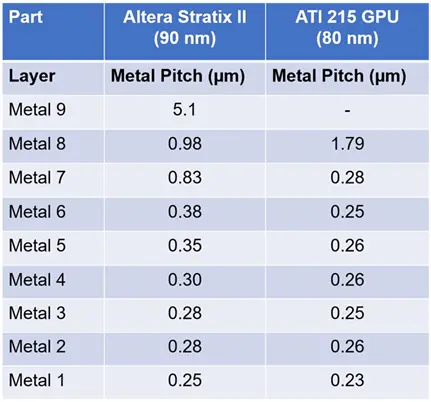
图18:90nm和80nm对比
但正如我们所见,结构上差别不大,SiOCN 阻挡层发生了细微变化,并且我们发现栅极长度略大一些。
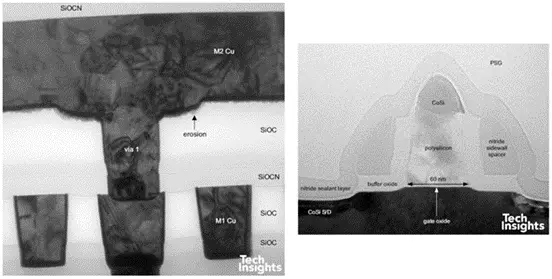
图 19:80 纳米 ATI GPU 的横截面
截至2006年底,IC Insights将台积电列为IC销售额全球第四大厂商,是全球最大的晶圆代工厂商,销售额比第一大晶圆代工厂商高出2.5倍以上。
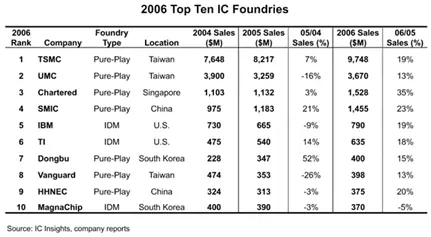
图20:2006年的十大IC代工厂
他们还将这两座300毫米晶圆厂命名为“GigaFab”,2006年第四季度其总产能为27.1万片300毫米晶圆。“这些‘GigaFabsSM’是我们不断努力提升制造卓越性并持续取得突破的核心。我们的GigaFabs通过实现近乎100%的自动化来降低运营成本,例如实时晶圆调度、用于自动化物料处理系统 (AMHS) 的搜索引擎优化路线、生产晶圆和非产品晶圆的全自动化,以及精益的在制品控制。”(2006年业务概览)
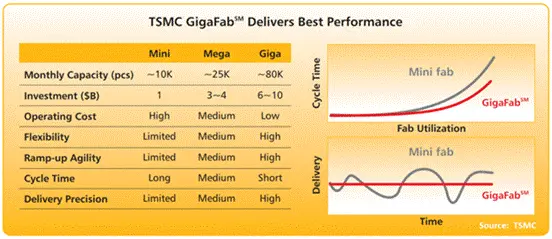
图21:台积电GigaFab提供最佳性能
下一个全节点是 65 纳米,我们发现了一个有趣的代工厂-客户定制案例。除了 Altera FPGA 之外,我们还发现了由台积电代工的德州仪器 (TI) 基带处理器。虽然后端堆栈相似,但我们发现晶体管结构存在显著差异。

图 22:(左)Altera FPGA 和 TI 基带处理器芯片密封的横截面
TI 部件的顶部铜层明显更厚(1.6 µm),适用于电感器等射频功能,而 FPGA 的顶部铜层厚度约为 0.85 µm;底部金属间距较小,以匹配 TI 的 65 nm 工艺。除此之外,底部金属/电介质堆叠相似。这款处理器是为诺基亚手机制造的,TI 使用自己的晶圆厂、联华电子和台积电来生产芯片;我们推测这款部件的产量相当大!下面是晶体管的示意图。
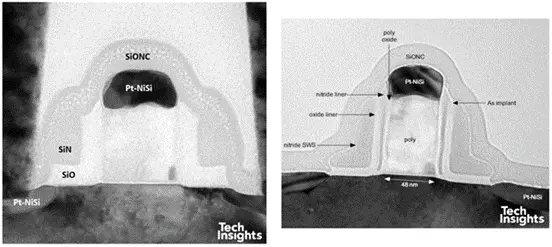
图 23:(左)Altera FPGA 和 TI 基带处理器的晶体管横截面
Altera 器件遵循 90 纳米和 80 纳米晶体管的趋势,改用铂掺杂的镍硅化物,并改进了(可能带有应力的)接触蚀刻停止层 (CESL)。TI 晶体管采用了其差分偏移间隔层 (DOS) 技术和台积电在 110 纳米工艺上已淘汰的 L 形间隔层 [5]。两种衬底均旋转 45 度,以形成 <100> 沟道。
2007年,台积电发布了一款55纳米、尺寸缩小10%的工艺,但台积电似乎没有分析过当时的任何同期产品。当然,下一代工艺的开发仍在进行中,在2007年的IEDM大会上,台积电展示了关于传统工艺(SOI)和高k金属栅极(HKMG)的45纳米工艺的论文。
从商业角度来看,2007年,飞利浦最终剥离了其持有的台积电股份。台积电可以说是当时半导体行业最成功的合资企业——飞利浦最初约1300万美元的投资在20年的合作中增长到超过100亿美元。产能也从约710万片晶圆(8英寸当量)增加到约830万片,占两座300毫米晶圆厂总产能的三分之二。
随着台积电开发出 45 纳米技术,英特尔推出了 45 纳米 HKMG 工艺,这是晶体管结构的一次重大变革,它取消了多晶硅栅极,并用复杂的金属堆栈取而代之。

图 24:英特尔 45 纳米晶体管的横截面
台积电在 45 纳米工艺上采取了更为保守的路线,尽管也做出了一些重大改进——浸没式光刻技术、极低介电常数 (ELK) 和应力晶体管。这些变化似乎减缓了 45 纳米工艺的引入,以至于该节点实际上被忽略了,而全面量产是在计划中的 40 纳米半节点上进行的。
从当时的评论来看,不仅仅是新工艺步骤的引入导致了问题,工艺/布局之间的相互作用也同样如此。“好吧,在这一代产品中,我们发现设计布局风格至关重要,因为在我们的产品中,我们确实看到设计存在差异——因为不同的产品有不同的良率表现,而且差异很大,我们发现对于那些良率低的产品来说,主要是因为设计对布局的依赖。我们所说的面向制造设计(DMT)是什么?简而言之,当设计规则无法完全描述设计时,我们会使用额外的算法软件来优化布局,以获得最佳良率。”(Mark Liu,2009 年第二季度分析师电话会议)。此外,还必须安装并运行新的计量系统。
2008年至2009年也遭遇了经济大衰退;2009年全球集成电路市场下滑了10%,不过2009年第四季度较第一季度大幅反弹47%。从台积电65/40纳米营收图表中可以清晰地看出这种影响。
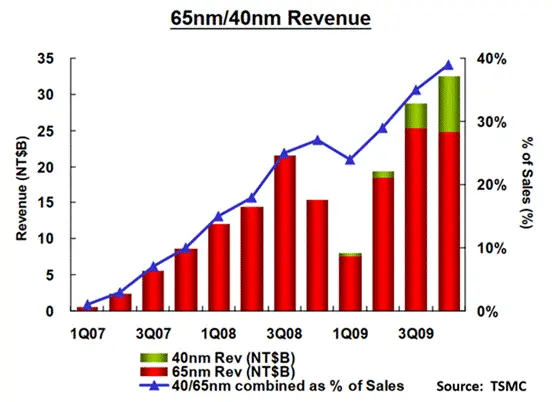
图25:65nm/40nm收入
40纳米工艺融合了45纳米工艺的改进,但在已发布的45纳米尺寸上仅进行了微小的缩小[6]。它最初提供三个版本:低功耗(LP)、通用(GP)和高性能(GS),后来又增加了超低性能版本。
对这三种工艺的分析表明,GS 工艺采用了双应力 CESL 氮化物(DSL:NMOS 为拉应力,PMOS 为压应力),并嵌入了 SiGe 源极/漏极以增加 PMOS 的压应力。GP 工艺也使用了 DSL,但 Ge 含量较低(19% vs. 26%);LP 工艺继续使用 DOS 隔离层和 <100> 沟道,但没有使用 DSL 或 e-SiGe。所有版本似乎都使用了 ELK(可能是 Black Diamond II)作为底层金属层。
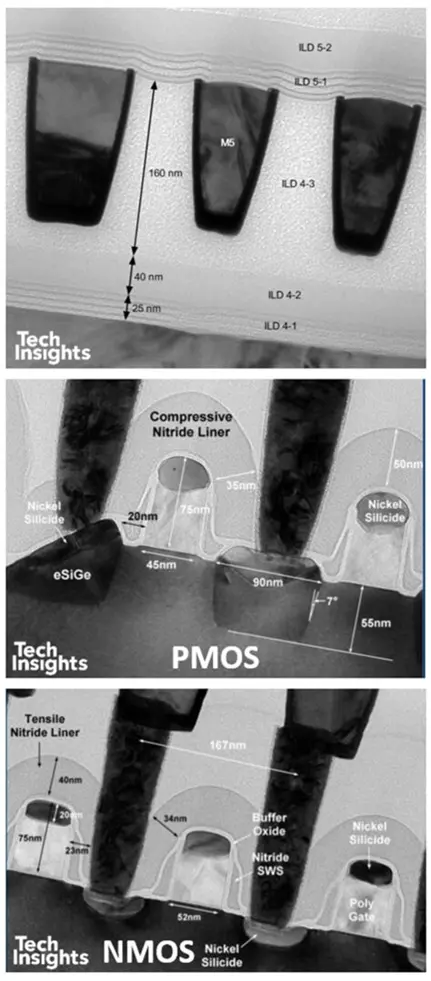
图 26:40 nm GS Altera FPGA ELK 电介质(顶部)和晶体管的横截面
截至2009年底,台积电已拥有超过400家客户,全年为其生产了超过7000种产品。十年间,台积电的晶圆出货量从180万片(8英寸当量)增长至2009年的770万片,年产能也从190万片提升至1000万片,这得益于300毫米晶圆厂扩建至Fab 12四期和Fab 14三期。因此,营收从约730亿新台币增长至约2960亿新台币,十年间增长超过400%。
在40纳米工艺的时代,台积电与其他正在推广45纳米产品的公司步调不一致。这种差距持续到下一个节点,台积电通常比英特尔和IBM等IDM厂商的工艺缩减了70%,而英特尔和IBM等IDM厂商则采用32纳米工艺。
第五阶段——
HKMG 及扩展、扩展、扩展
2010年7月,该公司宣布其位于台中市中部科学园区的第三座300毫米超级晶圆厂——Fab 15——破土动工,该项目将分为四期进行。第一期专注于40纳米和28纳米工艺,后续阶段则将专注于更高节点的工艺。到年底,Fab 12扩建至第四期,Fab 14扩建至第三期,产能提升37%,达到约250万片300毫米晶圆/年。
2007 年,英特尔采用后栅极替代金属栅极 (RMG) 技术在 45 纳米工艺中推出高 k 金属栅极 (HKMG),对 NMOS 和 PMOS 使用不同的功函数材料。
IBM 及其合作伙伴正在尝试替代的先栅极技术,该技术在高 k 介电层中使用不同的覆盖掺杂剂来区分 NMOS/PMOS,并在高 k 层上使用共用的金属和多晶硅。这不仅仅是栅极堆叠的差异——后栅极技术是指所有高温源/漏极工程都在高 k 沉积之前完成,并使用虚拟多晶硅栅极;而先栅极技术则将高 k 层暴露于高温源/漏极工艺中。
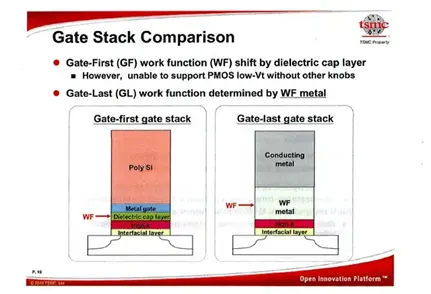
图27:2010年高管论坛的栅极堆栈比较
在开始 32 纳米研发之后,台积电在其 28 纳米工艺中并行开展了先栅极和后栅极 HKMG 项目,并最终确定采用后栅极工艺,正如台积电在 2010 年 2 月的高管论坛上宣布的那样。
他们还透露,将提供三个版本,分别是高性能(28HP)和使用 HKMG(28HPL)的中速、低泄漏品种,以及采用传统多晶硅栅极的 28LP 低功耗 [3],后来用于移动的 28HPM(也是 HKMG)也被添加到列表中。
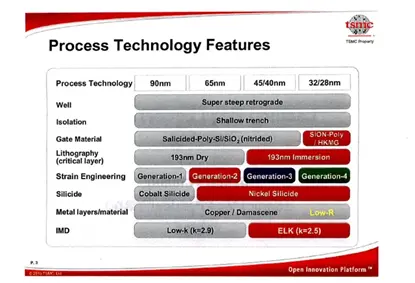
图28: 2010年高管论坛流程对比
从 45 纳米和 40 纳米延迟的经验中,引入了限制设计规则来减少变化并提高产量:

图29: 28纳米节点的限制设计规则
与 40 纳米一样,28LP 继续使用差异氧化物间隔物 (DOS),但这次使用嵌入式 SiGe 作为 PMOS,并且没有使用双应力衬里。
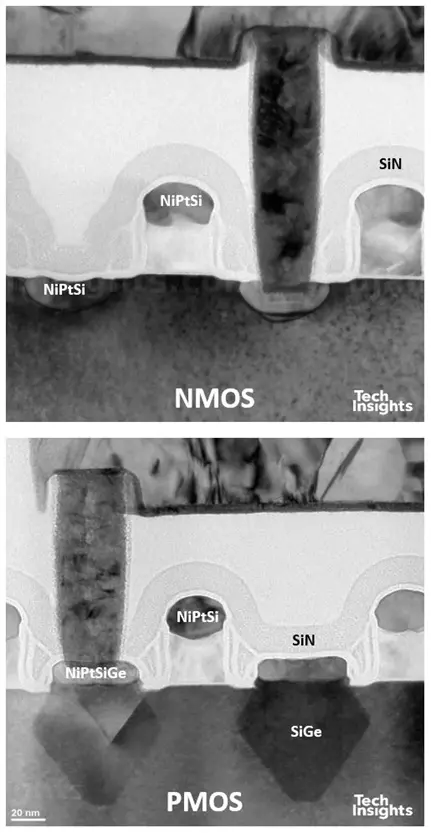
图30:联发科SoC中台积电28LP晶体管的横截面
通过将Ge含量增加到40%并使用选择性(111)腔体蚀刻,e-SiGe应变得到增强,并且可能在接触蚀刻停止层中存在一些拉应力。沟道方向恢复到<110>。
转向 HKMG 工艺,Xilinx 为其 Kintex-7 FPGA 采用了 28HPL:

图31:Xilinx Kintex 7 FPGA中TSMC 28HPL晶体管的横截面
高k层及其界面氧化物先形成,然后是虚拟多晶硅栅极(先形成高k层),并且DOS隔离层已演变为三重SiN/SiO/SiN隔离层。为了符合低功耗设计,虽然我们采用了<100>沟道方向,但没有采用嵌入式SiGe来增强PMOS。
Altera 选择在其 Stratix-V 产品中使用 28HP,虽然 NMOS 晶体管看起来非常相似,但 PMOS 受益于 e-SiGe,Ge 含量高达约 50%:

图32:Altera Stratix-V FPGA中台积电28HP晶体管的横截面
作为参考,这些是英特尔 45 纳米晶体管:

图33:英特尔45纳米晶体管的横截面
栅极堆叠相似但不完全相同,它们使用的功函数材料也类似。一个显著的区别是替换金属的顺序——英特尔先形成PMOS金属堆叠,然后在NMOS区域进行蚀刻,再沉积NMOS堆叠;台积电则相反,先铺设NMOS,进行蚀刻,然后填充PMOS金属。

图34:高通APU中台积电28HPM门电路的线性部分
最后,28HPM 似乎具有相同的栅极 HKMG 栅极堆叠,但最小栅极长度更短(32 纳米 -> 27 纳米),并且 PMOS 源极/漏极的 Ge 含量降低至约 30%。28HP 和 28HPM 均具有 <110> 沟道方向,与 (111) 蚀刻的 SiGe 腔体保持一致。所有 28 纳米版本似乎都使用 ELK(可能是 Black Diamond II)作为底层金属层。

图35: 高通骁龙800中台积电28HPM晶体管的横截面
下表总结了这些过程。
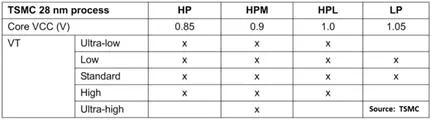
表 1. 28 纳米工艺变体
台积电还在 2010 年高管论坛上宣布,他们的下一个节点将是 20 纳米而不是 22 纳米,保持 70% 的缩小率,预计在 2012 年推出。
与此同时,Fab 15二期于2011年年中开工建设,三期于12月破土动工;一期设备已完成搬入,计划于2012年初实现量产。截至2011年底,Fab 12和Fab 14的月产能已超过27万片晶圆,Fab 15竣工后预计将使月产能增加10万片以上。尽管2011年充满挑战,全球半导体市场增长接近于零,但这一年依然取得了显著成绩。
2011年业务概览宣布了CoWoS 3D芯片堆叠的开发;“2011年,我们展示了一个功能齐全的子系统,其逻辑芯片内置无源元件和凸块,全部由台积电使用我们专有的晶圆基板芯片(CoWoSTM)技术制造和组装。”
CoWoS 是台积电全新先进封装开发的一部分,但这是一个很大的话题,应该作为单独的博客来介绍。
在研发方面,经过三年的摸索和28纳米和20纳米FinFET晶体管能力的展示,他们也开始了14纳米FinFET的全面开发。他们还启动了450毫米项目,并加入了位于纽约州奥尔巴尼的G450C(全球450毫米联盟)——当然,该联盟最终解散了。
2012年和2013年,28纳米制程产能扩张,分别占到年终营收的22%和34%。2014年初,20纳米产品开始量产,并随着产能的快速提升,到第四季度,得益于其在主流智能手机中的应用,28纳米制程的产能占到了公司年营收的42%。
20纳米节点要求对关键层使用双重曝光技术,因为它突破了光刻技术单次曝光分辨率的极限,标称Mx间距为64纳米。它还引入了单栅极扩散断层和M0局部互连。
在晶体管结构方面,栅极堆叠最后移至高k,沉积在多晶硅去除后沉积的高k介电层。
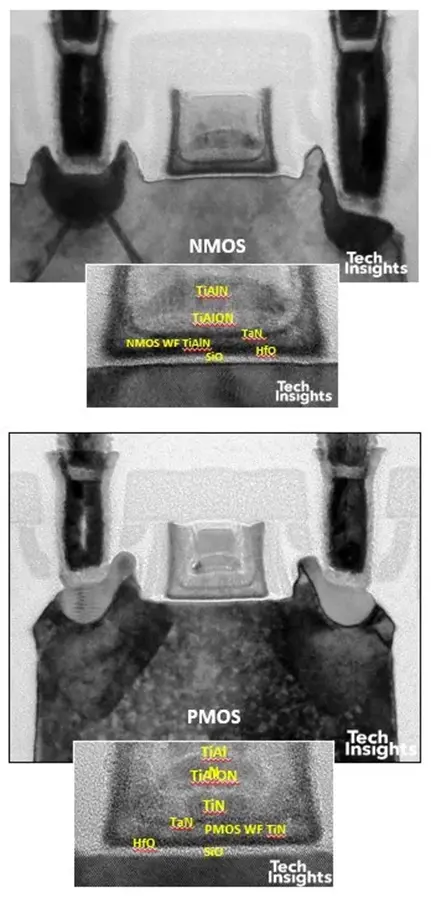
图36:高通调制解调器中台积电20HPM晶体管的横截面
替换金属的序列又恢复到了英特尔的风格,即先PMOS,再NMOS;并且通过使用堆垛层错来增强NMOS的应力。
图37:NMOS栅极和源极/漏极的横截面(顶部)以及台积电20HPM晶体管的栅极线性部分(底部)
堆垛层错通常不是我们希望在晶体管中看到的,因为如果它们穿过结点,它们可能会泄漏,但只要它们包含在源极/漏极扩散内,它们就不会成为问题。
从直观的层面来看,这种机制是合理的——堆垛层错是指晶格中原子层缺失,而栅极长度约为 28 纳米,我们现在处理的沟道长度只有一百个原子间距或更小。因此,如果沟道两端缺失几个原子层,那么在沟道中产生拉应力似乎是合乎逻辑的。
后来,台积电将工艺推进到22nm、16nm、10nm、7nm、5nm、3nm以后,他们一骑绝尘,再无对手。公司也将晶圆厂扩展到美国、欧洲和日本,成为空前的霸主。