Anthropic推出Claude Opus 4.8 编码能力与“诚实度”双双升级
Anthropic 今日正式发布最新一代大型语言模型 Claude Opus 4.8,重点强化在代码生成、多学科推理、自动操作电脑、知识型工作以及金融分析等“代理型”(agentic)任务中的表现,被官方形容为“更高效的协作伙伴”。 参与测试的用户反馈称,Opus 4.8 在执行复杂代理任务时表现更可靠、判断更敏锐,同时在诚实性方面也有明显改进。

Anthropic 表示,早期测试结果显示,Opus 4.8 更倾向于主动标注自身不确定之处,更少做出缺乏依据的断言。 内部评估数据显示,相比前一版本,Opus 4.8 在自己生成的代码中放过错误不提及的概率约降低了四倍,这意味着模型在代码审查与质量控制环节的“自我纠错”能力显著增强。
在对齐性(alignment)测试中,Opus 4.8 在支持用户自主决策、维护用户最大利益等“亲社会特质”方面创下新高。 与之相对,诸如隐性欺骗、误导性行为等“失配行为”的发生率低于 Opus 4.7,并与此前仅向少量机构测试开放的 Claude Mythos 预览模型处于同一水平。
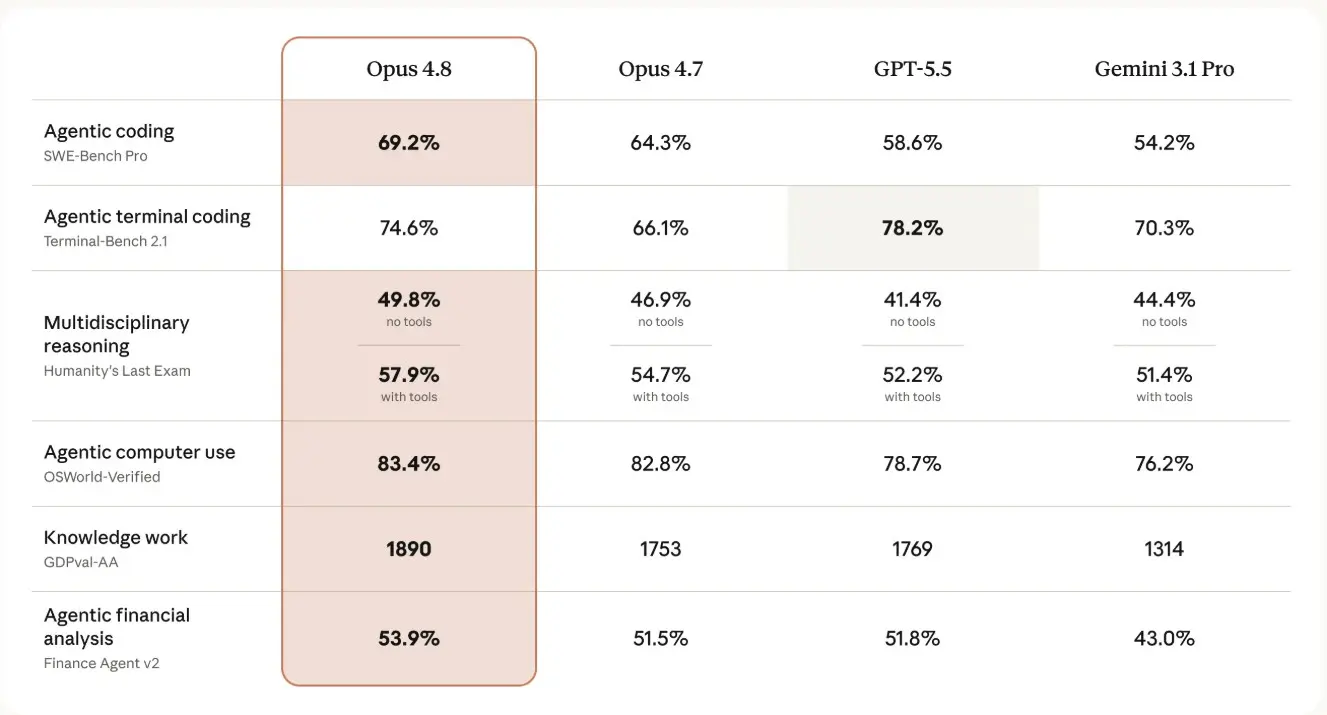
在多项公开基准测试上,Anthropic 也给出了具体成绩:Opus 4.8 在软件工程基准 SWE‑Bench Pro 上取得了 69.2% 的得分,超过了 GPT‑5.5 和 Gemini 3.1 Pro 等竞品模型,在多个测试项目中占据优势,不过在终端编码类基准上仍由 GPT‑5.5 领先。 在性能方面,Opus 4.8 的快速模式推理速度提升至此前的 2.5 倍,价格则降至旧型号的约三分之一,使得高性能使用的整体门槛进一步降低。
配合新模型上线,Anthropic 还宣布为产品体系加入多项新功能,其中包括面向企业开发者的“动态工作流”(研究预览)。 这项功能允许 Claude 在 Claude Code 环境中拆解大型任务、规划工作步骤,并在单个会话内并行调度数百个子代理,从而完成跨数十万行代码的代码库级迁移操作,目前面向 Claude Code 企业版、团队版和 Max 订阅计划开放。
在交互控制方面,Anthropic 新增了“努力程度控制”功能,供 Claude.ai 与 Cowork 用户选择模型在单次回答中投入的计算资源与推理深度。 用户若选择较低努力等级,可以获得更快的响应速度并减少速率配额消耗,而 Opus 4.8 默认采用“高努力”模式,官方认为这是回答质量与使用体验之间的最佳平衡点。
针对开发者,Anthropic 更新了 Messages API,使其能够在消息数组中接受系统级指令条目。 这意味着开发者可在任务执行过程中动态调整 Claude 的行为准则与角色设定,而无需重新开启新会话,有助于构建更灵活的多步骤自动化工作流和企业级应用。
Anthropic 表示,Claude Opus 4.8 即日起在全球范围内全面开放使用,其常规用量的定价与 Opus 4.7 保持不变。 公司同时透露,正研发在相同功能水平下成本更低的新模型,以及一类能力超过 Opus 4.8 的“下一代”模型产品。
在高阶模型路线图方面,Anthropic 正与少数合作机构测试代号为 Claude Mythos 的前沿模型,并围绕该模型持续开发更严格的安全护栏与使用规范。 公司称,预计将在“未来数周内”向全部客户提供 Mythos 级模型,进一步拓展其在企业级安全审计、代码分析以及复杂决策支持等场景中的竞争力。