最强编程AI被指降智 官方紧急回应被群嘲:缩水也叫优化?
最强的编程AI,到底降没降智?今年2月初,Anthropic发布Claude Opus 4.6,其凭借着深邃的推理逻辑和对复杂代码规范的精准执行,被业界奉为代码真神。然而好景不长,发布仅数周后就不断有用户在社交媒体上声讨,称其性能出现了断崖式下跌。

不少用户声称自己付着同样高昂的月费,换来的却是一个被明显降智的缩水版本,Opus 4.6开始变得懒惰与健忘,甚至在基础逻辑里反复撞墙。
面对全网的声讨,Anthropic官方团队出面回应,他们辩称从未削弱模型,种种异常表现只是为了帮用户节省Token而做出的默认配置优化。
这种单方面的技术辩解显然无法平息开发者的怒火。
这究竟是大量用户的集体心理错觉,还是资本在算力瓶颈下精心炮制的缩水?
一、AMD高管的深度分析:6852份日志见端倪
如果说普通用户的抱怨只是体感,那么斯特拉·劳伦佐(Stella Laurenzo)的分析,则是让这件事彻底“实锤”了。
根据领英资料,劳伦佐是AMD的AI部门高级总监,目前在AMD领导一支庞大的团队为开源AI编译器开发贡献力量。她曾在谷歌担任首席软件工程师,后作为前Nod.ai工程副总裁加入AMD。
4月2日,劳伦佐在GitHub上发布了一份详尽的性能回溯报告。
作为一名顶级AI专家,她没有只凭直觉说话,而是详细分析了6852份Claude Code会话文件与17871个思考块以及超过23万次工具调用记录,堪称一份详尽的高水平个案研究。
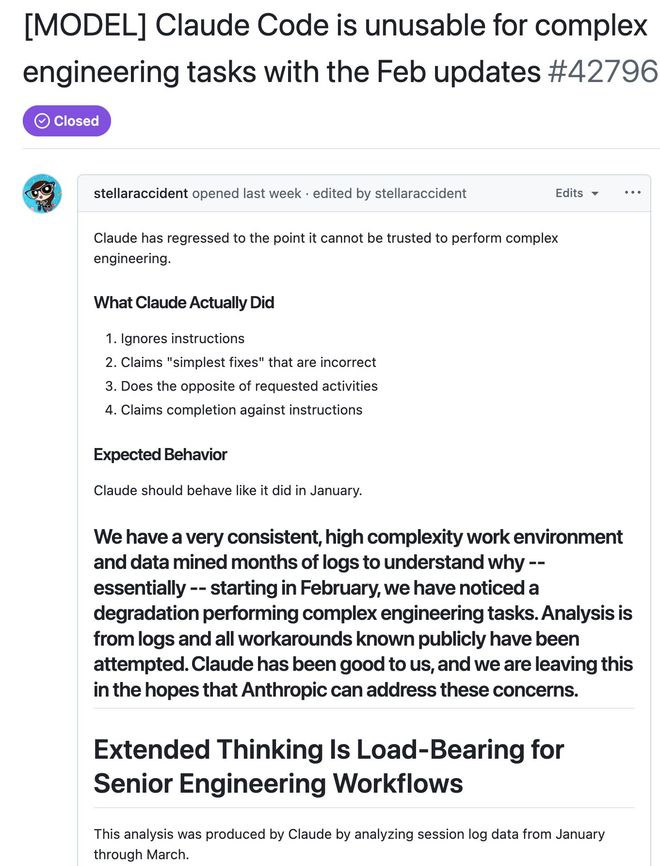
这份基于海量数据的分析揭露了一个令人不安的真相,从今年2月份开始,Claude的推理深度就出现了断崖式下跌。
细节信息显示:
推理字数缩减:中位思考长度从2200字符缩减到了600字符。
研究退化:以前Claude在写代码前会进行多轮研究(Research),现在的模式变成了直接上手改(Edit),这导致读取与编辑的比率从6.6倍降至2.0倍。
任务早退:在短短17天内,Claude尝试放弃任务或反问我是否应该继续的次数达到了173次,而在3月8日之前这个数字是0。
自相矛盾:推理过程中的自我否定(如“哦等等,实际上……”)频率增加了三倍。
劳伦佐的结论非常冷酷,对于高级工程工作流来说,深度推理不是奢侈品而是模型可用的前提,现在Claude在复杂工程中已经靠不住了。
不过需要注意的是,劳伦佐的分析结论只是说今年2月底Claude思考长度缩短了67%,推文将思考量减少直接等同于智力下降的说法难论严谨。
二、社交媒体的证言墙:40分钟的思考与无效的账单
劳伦佐的帖子迅速引爆了社交媒体X和Reddit,无数开发者发现自己遇到的问题与这份报告高度契合。
网红开发者奥姆·帕特尔(Om Patel)直接在X上贴出了结论,有人测出了Claude变笨了多少,答案是67%。
他的论点主要集中在Opus 4.6的思考量比以前少了三分之二。他讽刺地写道,Anthropic一直保持沉默,直到这些数字被公开,他们的团队才出来灭火。
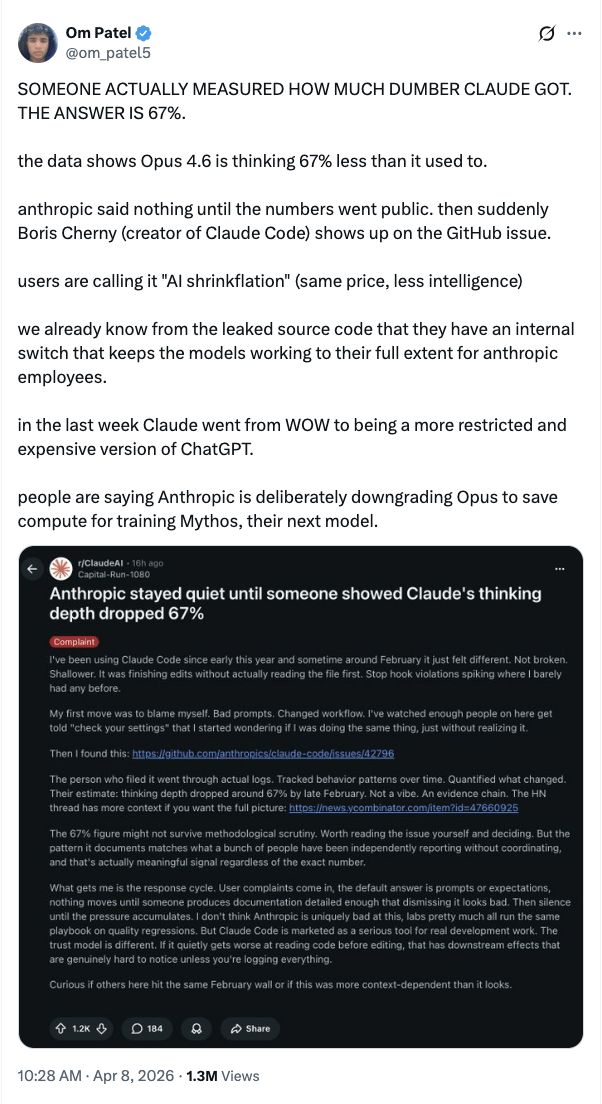
帕特尔还在推文中透露,泄露的源代码显示他们有一个内部开关,可以让模型在Anthropic员工使用时保持最佳状态。不过这一说法尚未得到独立验证,Anthropic也未对此作出回应。
他还直言,有人说Anthropic故意降低Opus的性能,是为了节省计算资源来训练他们的下一个模型Mythos。但这一推测同样缺乏直接证据。
在Reddit上,用户们的吐槽则更具具像化,也更显无奈:
坐等式思考:用户DangerousSetOfBewbs称他曾让Claude处理一个500行的文件,结果Claude进入了长达24分钟的思考中状态,只是在那里干坐着。还有网友附和,让它做研究,40分钟几乎没用什么Token,所以根本不清楚它这40分钟到底做了什么。
规则视若无睹:许多开发者习惯在CLAUDE.md中设定项目规范,但现在Claude仿佛患上了失忆症。一位用户愤怒地留言,如果你不盯着它的输出,它能分分钟毁掉你的代码库。
价格没变智力降级:这就是典型的缩水通胀。Reddit用户Firm_Meeting6350说,我今天退订了Claude Max 20并转投了Codex Pro,Claude现在给我的感觉就像在用过时的旧模型。
三、跑分迷雾:从第2名到第10名的跌落
如果用户抱怨还可以解释成主观感受,那么基准测试则似乎要拿真实数据讨说法。
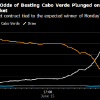
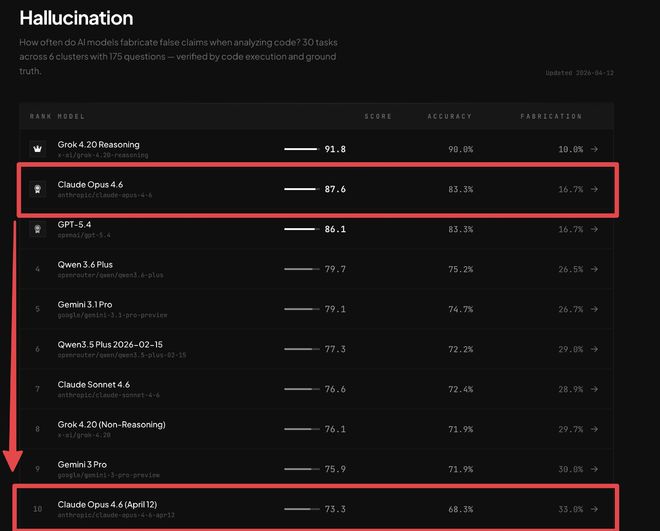
4月12日,专门负责幻觉基准测试的机构BridgeMind发布了一条推文,直接将争议推向高潮。
推文指出Claude Opus 4.6被削弱了,BridgeBench刚刚证明了这一点。上周它排名第2且准确率83.3%,今天重测它掉到了第10且准确率仅剩68.3%,幻觉率增加了98%。
然而这一测试结果遭到了反驳。外部AI研究员保罗·卡尔克拉夫特(Paul Calcraft)随后指出测试中存在误导性,BridgeMind的两次测试并不是对等比较。第一次测试只涵盖了6个任务,而第二次测试扩充到了30个任务。
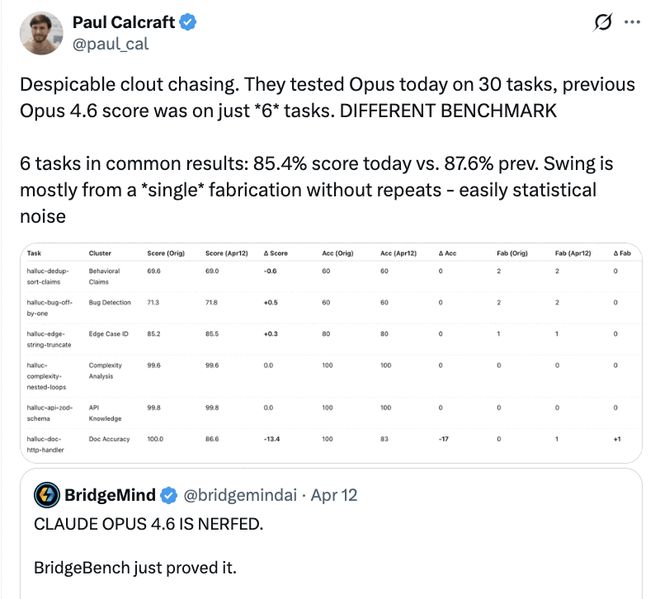
卡尔克拉夫特指出,如果只看那6个共同的任务,Claude的得分仅从87.6%轻微波动到85.4%,最大的偏差几乎来自于单个虚构结果,这种差异在统计学上完全可以归类为噪音。
这场跑分争议本身也说明,目前业界缺乏统一且可复现的AI性能基准测试标准,很多测试颇有先下结论后找论据的风格,用户很难从测试数据中获得确定性的答案。
然而那个跌落至第10名的数据在社交媒体上疯传,截图给人的视觉冲击力使其成为了Claude降智这一说法的最有力佐证。
四、官方回应:是优化而非削弱
面对汹汹民意,Anthropic的核心团队成员不得不公开回应。
Claude Code负责人鲍里斯·切尔尼(Boris Cherny)在劳伦佐的GitHub原文下认真解释了一通,并在X上连发数条回复,核心观点只有一个,他们没有削弱模型,只是为了响应用户反馈调低了默认的努力程度。
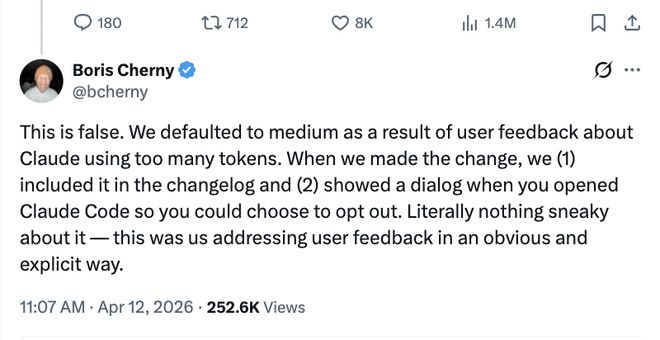
切尔尼表示,很多用户此前反馈Claude消耗Token太多。为了响应用户反馈,Anthropic做了以下改变:
默认努力度降级:在3月3日默认将推理努力度设置为中等,如果你想要深度推理,需要手动输入对应高级指令。
前端隐藏思考过程:改变了前端显示,不再完整展示思考块,减少了延迟,但这不影响思考预算或后端的深度推理。
自适应思考机制:在2月9日引入了动态调整机制。
Claude Code团队成员塔里克·希希帕尔(Thariq Shihipar)也力挺自己的部门老大,他连发数条推文用技术层面的解释打消用户疑虑,还坚称公司不会为了更好地满足需求而降低模型性能。
值得注意的是,切尔尼提到的默认努力度降级,恰好可以解释劳伦佐分析报告中的思考长度缩短与研究行为减少以及任务放弃频率上升等多种现象,这与推理处于中等的默认设置高度吻合。
然而官方解释并不能平息众怒,社交媒体上很多用户都认为,如果为了帮用户省钱而降低性能或者给出错误答案,那这种省钱根本毫无意义可言。
何况公司没通知就直接进行了调整,直接损害了用户的知情权。
五、幕后暗战:缓存生存时间与算力瓶颈
除了推理深度的变化,不少用户还注意到Claude变得更贵了。
GitHub上一份编号为46829的反馈指出,Claude Code的提示词缓存生存时间从原本的1小时被缩短到了5分钟。

这意味着对于长时间工作的程序员来说,你刚才跟Claude说的话,5分钟后它就忘了。为了继续工作,你需要重新上传上下文。
这不仅增加了延迟,更让用户的Token消耗量激增,使得一些订阅用户开始触及以前从未遇到的使用上限。
Anthropic工程师贾里德·萨姆纳(Jarred Sumner)承认了3月6日的这一改变,但辩称这是为了持续的缓存优化工作而不是暗中降级。在开发者眼中,这无异于证实了官方确实在后台积极调整缓存行为,而这正是大家抱怨配额消耗过快的时间段。
不管是Claude变笨也好变贵也罢,Reddit网友raven2cz的说辞堪称一语中的。
这两大问题也就是额度限制和思考能力下降都与基础设施过载密切相关,去GitHub上看看就知道了,成千上万的用户现在都在面临类似的问题,这情况感觉就像一年半前GPT发布新模型时一样。
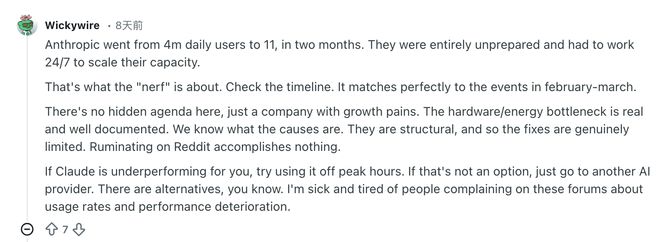
网友Wickywire则分析了其中的根本原因,Anthropic在两个月内日活用户从400万涨到了1100万,他们完全没有准备并不得不全天候连轴转去拼命扩容,这就是所谓削弱的真相。你去对时间线,和二三月份发生的事完全吻合。
这里没有任何隐藏的意图,只是一个经历增长之痛的公司,硬件与能源的瓶颈是真实且证据确凿的。
我们知道原因所在且它们都是结构性的,所以解决办法也确实有限,在Reddit上反复纠结毫无意义。
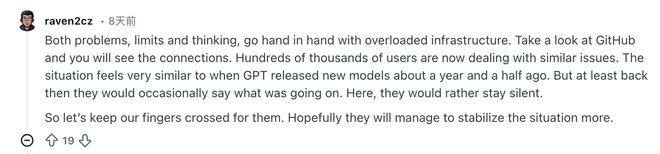
这位网友给出的解决方法倒是立竿见影且切实可行,如果你觉得Claude表现不佳可以试试在非高峰时段使用,如果不行换别家AI服务商也行,反正又不是没有选择,真是受够了那些在论坛上抱怨使用量和性能下降的人了。
六、结语:信任危机比变笨更可怕
目前的局面是,用户在描述体感,而Anthropic在描述参数。
用户觉得它变笨了且任务失败了,官方则表示没有动权重,只是改了默认努力值与缩短了缓存以及调整了前端显示并公开披露过。
这两种描述其实并不矛盾,在AI领域即便公司认为自己没有在底层削弱模型,但微妙的设置变化和配额限制,对全天候依赖它的开发者来说体验上与变笨毫无二致。
当开发者开始怀疑一个工具的稳定性时,这种信任的裂痕是极难修复的。
尤其是在强敌环伺的当下,OpenAI的Codex正在步步紧逼,它凭借更稳定的算力输出与灵活的中阶订阅及全新的交互功能,精准收割失望的开发者。
第三方开发者调研工具显示,自今年3月底Claude降智传闻发酵以来,Codex及其相关插件的周新增用户量环比增长了约22%。
如果Anthropic无法在节省算力成本与维持深度推理之间找到真正的平衡点,那么Claude辛辛苦苦建立起的口碑恐怕将在这场风波中受到考验。
有老用户所说,我宁愿付两倍的钱买一个聪明的Claude,也不愿花同样的钱买一个只会说道歉并要求更多信息的笨蛋。
这场AI界的性能拉锯战才刚刚开始。