不知道大家有没有发现,这年头,连输入法都越来越难用。它不是完完全全的不好用,而是暗搓搓有意识的难用,就像是似乎明明知道你想打什么字,可偏偏跟你对着干,故意针对你。最普遍的就是常用字离奇失踪,比如“是”字,经常会被“事”挤到了首位;你明明想打“难用”,结果首选字却是“男用”。
不仅常用字拿不到优先级,词语解析也经常错得匪夷所思。
想打"从右到左",它给你蹦出来"葱油刀座";程序员想输入一个“Python”,结果出来的是“屁眼通红”;

想打个"毅力",首选是"伊利",这还引得不少人觉得这是在夹带私货。

成语和古诗词的联想能力也断崖式下滑,敲下“ypzyflbylh”,以前能完美识别出“有朋自远方来不亦乐乎”,可现在,它愣是能给你整出“油泼辣子衣服”;
想输入“偏我来时不逢春”,结果被识别成“骗我老师不丰唇”???

还有的时候,你打了一个词,下意识按了确认,一看,选错了,你要的字在第二个。
于是你重新打一遍,这次学乖了,直接按2,结果输入法也预判了你的预判,把你上次误选的那个词顶到了第二位,正确的字反而回到了第一个。
你以为这是安卓第三方输入法独有的问题?那苹果党就高兴得太早了。
iOS 26 升级完后,很多用户就反馈中文拼音输入大幅降级,联想功能大退步,以前能完整联想出一句话,现在只能两三个字两三个字地分开输入。
比如输入 woyebuzhidao,你觉得首选应该是"我也不知道"对吧?不好意思,它给你的是"玩噢也不织大啊噢";输入 nidaodizaiganshenme,首选是"你大噢递大噢肝什么"。

玩噢也不织大啊噢苹果大噢递大噢肝什么!!!
我们去看了下,类似关于输入法降智吐槽,可以说是江湖上传闻已久的"鬼故事"了。
只是到了如今这年头,一遇到这种"反向智能"的事儿,大伙儿已经开始习惯性地就把锅甩给 AI 了。
但实际上,这锅还真不能全让 AI 背。
今年 1 月,搜狗就专门给 AI 解释过,他们表示输入法的核心底座是对拼音串、词和用途的理解,AI 不会污染这些环节,官方甚至还说,我们输入法压根没变笨呀。

根据后台数据显示,打字准确率是在逐年缓慢提升的,这可和大家的感觉不太一样。
其实就是两者对于准确的定义不一样,在输入法工程师这边,只要目标词出现在候选框前五,就算输入成功;但对用户来说,第一下出来的不是想要的词,这输入法就是个智障。
那既然不是 AI 的锅,那到底是为什么?
第一个就是,互联网语料大爆炸,导致数据被严重污染。
输入法到底是怎么知道你想打什么字的?
简单说,它背后有一个巨大的统计语言模型,基于概率论,利用前文推测下一个最高频出现的字词。
以前这套系统跑得挺好的,因为早期互联网用户少,词汇量相对集中,一套通用的云端词库(语料主要来自新闻、出版物、标准网页文本,词频分布非常稳定)就能覆盖绝大多数人的输入需求。
但现在可不一样了,电竞圈、二次元、饭圈、短视频等等市场,每天都在以指数级的速度创造和抛弃海量词汇。
输入法的词库为了满足这些人的需求,就得不断扩容语料来源。
为了覆盖这些新词,厂商不得不大规模引入电商搜索日志、短视频评论区等口语语料。
数据量上去了,质量却跌没了。

当然了,污染更狠的可能还是用户自己,不少人打字时并没那么严谨,大量拼音半吊子打出的错别字,消息也照发不误,比如句末语气词“呀”经常被打成“压”或“亚”,就问谁还没被自家爸妈的错别字整懵过?
这事儿搁我们人类可能还好办,根据上下文和聊天对象猜一猜,就能搞明白了。
可对输入法来说,这些带着错字的文本进入词库后,它也搞不清到底谁对谁错。
也有一些人,因为平台审核严苛,故意用错字来避嫌(比如播播间之类的词语),也在进一步污染输入法的词库。

讽刺的是,这些情况的发生,并不是输入法变笨了,而是它们变聪明付出的代价。
很多吐槽输入法的帖子里,总有人在怀念功能机时代,那时候拿个小灵通回消息都能揣口袋里盲打,所以不少人觉得那才是高明。
但说实话,当时大家能觉得好用,恰恰是因为输入法太笨了,一个键对应三四个字母,词库固定得死死的,联想功能约等于没有。
这么一来,字词排序永远固定,你打到某个阶段,哪个字出现在第几个位置,是确定的。

用久了,手指会形成肌肉记忆,按几下确认键、往下翻几格,全是自动化操作,它的好用完全是人在适应工具。
现在的输入法变聪明了,它要主动学习你、预测你、适应你,结果因为词频不断改变,候选字的位置也是动态的,昨天第一个字还是"是",结果今天就变成了"事",用户根本来不及形成肌肉记忆,从而进一步加深了不好用的印象。
而且,还有个不能忽视的原因,搁以前换手机啥的,登录账号,词库就跟着走。用了多少年的输入习惯,完全不会丢,而这有一部分靠的是激进的数据收集和云端同步。
但这几年,《个人信息保护法》、《数据安全法》相继落地执行,输入法厂商在数据采集上被迫全面收缩。

云端词库同步不一定是默认开启的,必须用户主动绑定账户、主动授权,不少人换一个设备就得从头训练输入法,自然也就觉得不好用了。
那这么说厂商就全没锅了吗?那倒也未必。
因为搜狗、讯飞、百度三家占了第三方手机输入法 96% 的市场份额,整个市场就像一滩死水。
你去看看搜狗、讯飞、百度,长久以来的更新公告基本就是"修复已知 bug",QQ 输入法上次 PC 端有实质性更新还要追溯好几年前了。
那他们的重心就改到了皮肤、广告、添加乱七八糟的新功能上了,谁还费劲巴拉卷输入准确率呢?
而且移动互联网浪潮后,PC 端输入法的冷落已经到了厂商自己都得承认的地步了,搜狗就说过电脑端的更新速度远慢于手机 APP 端。
可真正对输入法需求高的场景,反而就是在 PC 端,在这些时候遇到的输入法错误,会被放大成对整个输入法品牌变笨了的整体印象。
说了这么多输入法的罪状,是不是有点绝望了?但别急,事情已经有了转机了。

前面说了输入法变难用不能怪 AI,实际上不仅不能怪 AI,输入法想要迎来质的飞跃,最后还得靠 AI。
这里说的 AI 不是那些什么“帮写”“帮你高情商回复”“一键联想搜索”这些花里胡哨的功能,而是实实在在利用大模型的能力,提升输入法的水平。
还记得我们前面说的,输入法到底最应该做的,就是拥有人类一样的思维,猜你想说什么、想表达什么。
巧了,这尼玛不就是 AI 大模型的工作原理吗?
所以你也能看到,这两年,腾讯的微信输入法和字节的豆包输入法先后入场,我们编辑部不少都已经成了两者的义务推广员了。
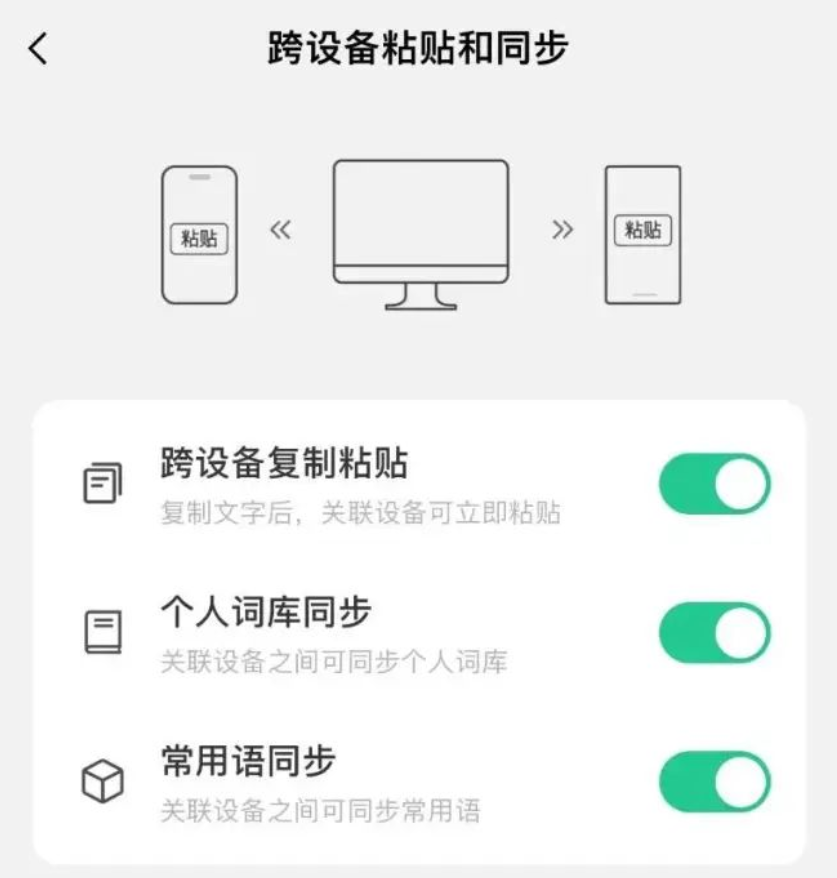
一边是微信输入法凭借自家生态,通过跨设备传文件的独特卖点,成功啃下一块市场。
随后,豆包输入法也没有在键盘打字层面和老牌输入法硬卷功能,它们直接用字节自家的 Seed-ASR 语音识别模型做了个降维打击。
这个模型在公开测试集上的错误率,相比国内同类模型最高可降低约四成。
什么概念?就是那种你前脚说完,后脚文字已经识别好了,标点也加了,大小写也规范了。有时候我甚至嘴瓢了说错词,它也能根据上下文帮我纠正过来。
而且,这哥们是真有上下文联想能力。
我们编辑部现在经常讨论 Claude 这个 AI 模型,语音输入的时候,一开始它会识别成 Cloud——毕竟发音差不多嘛。但当后面又提到了"大模型""AI"这些关键词的时候,它会自动把前面识别的 Cloud 纠正成 Claude,而且整个过程非常快,几乎是实时修正,相当丝滑。
过去二十年,输入法从一个纯粹的打字工具,变成了一个广告容器、一个功能大杂烩、一个被隐私法规束缚住手脚的数据孤岛,互联网语料爆炸污染了它的词库,商业化过度掏空了它的内核,旧技术架构走到了尽头。
但随着新入场的输入法选手们开卷,也让我们看到了一种可能性:输入法的未来,不是帮你写情书,不是帮你编朋友圈文案。
而是安安静静地待在屏幕下方,把你的肌肉记忆还给你。
当它真正做到让你不需要低头看候选词的那一天,那个好用的输入法,才算真正回来了。