今天凌晨1点,OpenAI接连扔出AI语音能力的两个重磅更新。一个是Realtime API,可支持生产级的实时智能体。另一个是最先进的语音到语音模型gpt-realtime。
Realtime API更新后不仅能连远程MCP服务器,识别图像输入,还能通过SIP协议直接打电话。
新模型gpt-realtime更是狠,复杂指令都能听懂,工具调用更精准,语音自然流畅,还能带点表现力。
它能逐字念免责声明,能准确复述字母数字,还能在对话里无缝切换语言。

最惊艳的,还是那声音效果,几乎和真人没区别,甚至比真人更惟妙惟肖。
先来感受下这个语音的夸张效果,你几乎听不出来“机器味”。
这不禁让人联想到OpenAl这两天很多人在社交媒体表示“feel the AGI....”
不知道说的是不是这个最新的Realtime语音功能。
在OpenAI提供的官方示例中,语音能力的加入,让整个画面立即就是充满了AGI的味道!
现在gpt-realtime能够处理复杂的多步骤请求,例如根据生活方式需求缩小房源列表,全程对话让AI完成操作。
或者直接拨打电话安排医生预约。
Realtime API第一次开放测试版是在去年10月,数千名开发者参与,边用边反馈。是所有这些开发者塑造了今天的改进。
高可靠性、低延迟、高品质,就是为了让语音智能体能够真正能落地。
因为AI语音实现的传统链路很繁琐:语音转文本,文本再转语音,层层叠加。
而Realtime API不一样,它只用一个模型,一个接口。
直接处理,直接生成音频。延迟更低,细节保留得更好。
声音,也更自然,更有表现力。

gpt-realtime 模型介绍
全新的语音到语音模型gpt-realtime,在音质、智能、指令遵循和函数调用方面均实现了全面提升。
可以说是OpenAI目前最先进的,并且也是已为生产环境准备就绪的语音模型。

音频质量
自然的对话是语音智能体在现实世界中落地的关键,就像电影《HER》中主角完全沉浸在斯嘉丽约翰逊的声音中。
所以要求模型需要具备媲美人类的语调、情感和语速,才能创造愉悦的体验,并鼓励用户持续交流。
OpenAI对gpt-realtime的训练专注于生成音质更佳、听感更自然的语音,并能遵循细粒度指令。
例如“用快速、专业的语气说话”或“带上法国口音,用共情的语气表达”。
此外,在API中推出了Marin和Cedar两款新语音,在语音的自然度上实现了重大突破。
同时,对现有的八款语音也进行了升级,使其同样受益于这些改进。
智能与理解力
gpt-realtime展现出更高的智能水平,能够更精准地理解原始音频。
模型可以捕捉笑声等非语言线索,在句子中途切换语言,并根据要求调整语气(例如,从“干脆利落的专业风格”切换到“亲切有同理心”)。
内部评估显示,该模型在识别西班牙语、中文、日语、法语等语言中的字母数字序列(如电话号码、车辆识别码等)时,表现也更为准确。
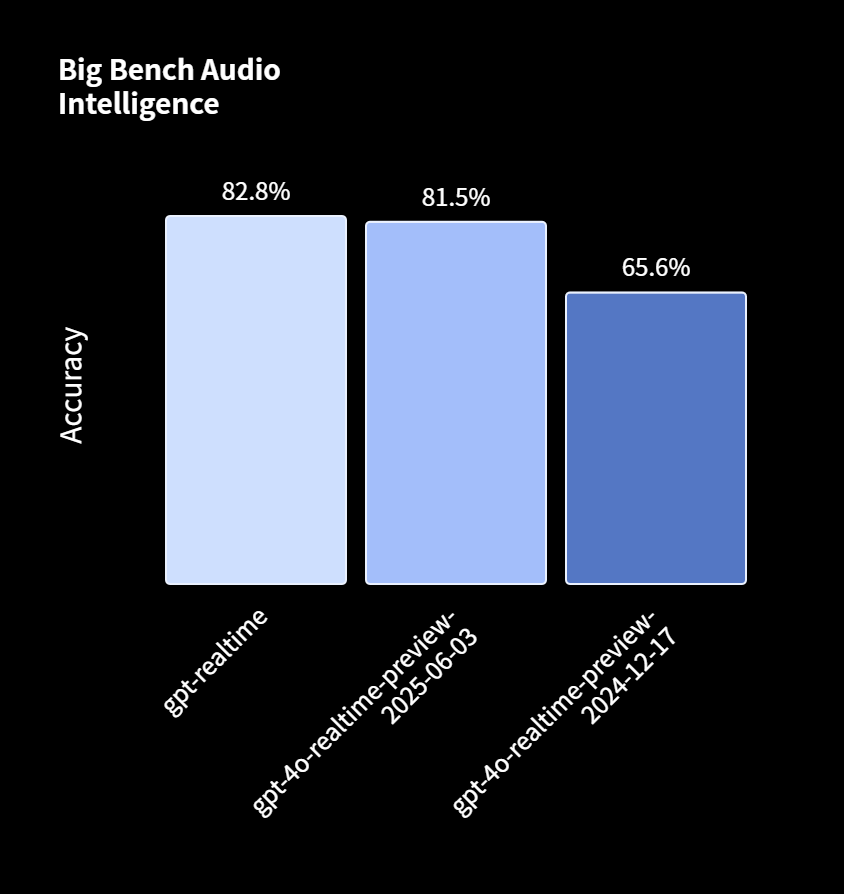
在衡量推理能力的Big Bench Audio评测中,gpt-realtime取得了 82.8% 的准确率,远超在2024年12月发布的上一版模型(65.6%)。
指令遵循
构建语音到语音应用时,开发者需要为模型提供一套行为指令,包括如何说话、在特定情境下说什么、以及行为的边界。
此次着重改进了模型对这些指令的遵循能力,使得即便是最细微的指示也能被模型有效捕捉。
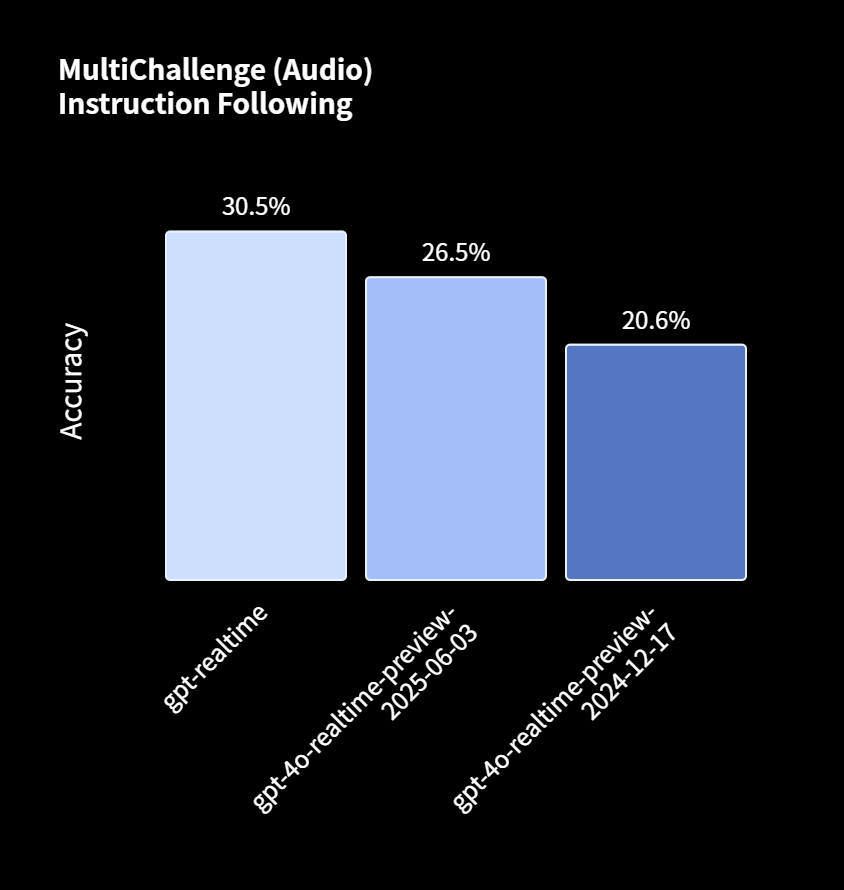
在衡量指令遵循准确度的MultiChallenge音频基准测试中,gpt-realtime的得分达到30.5%,相较于旧版模型(20.6%)有了显著提高。
函数调用
要利用语音到语音模型构建强大的语音智能体,模型必须能够在恰当的时机调用正确的工具,才能在生产环境中真正发挥作用。
gpt-realtime从三个维度改进了函数调用:调用相关函数、在合适的时机调用,以及使用正确的参数调用(从而提升准确率)。
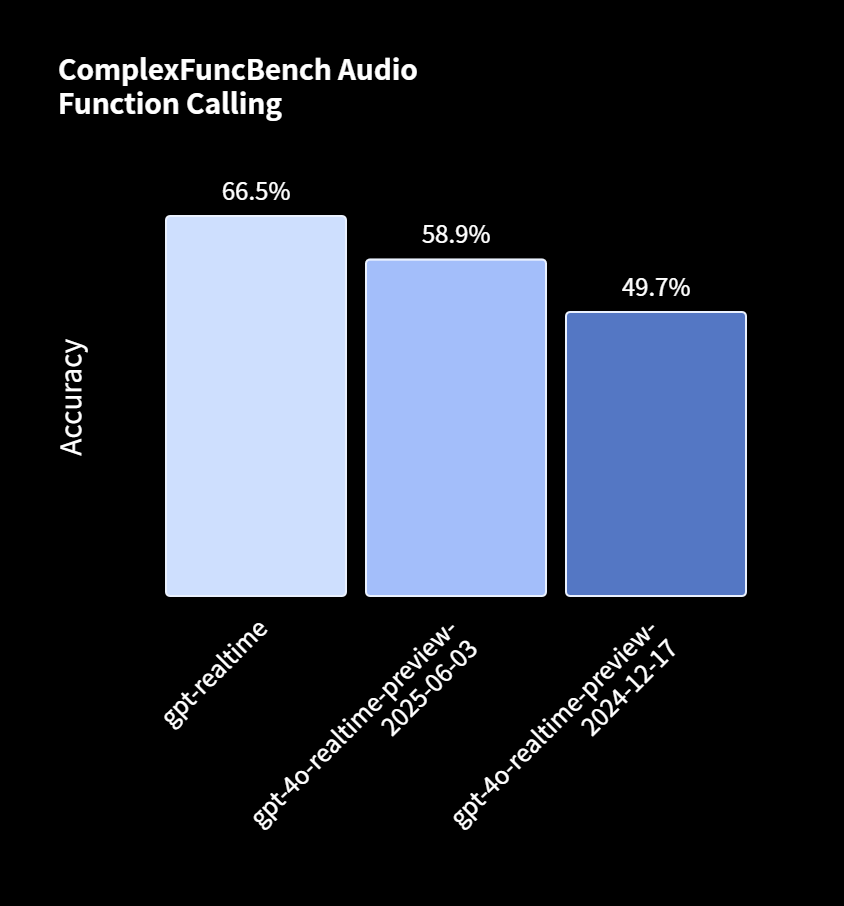
在衡量函数调用性能的ComplexFuncBench音频评测中,gpt-realtime的得分为66.5%,而旧版模型得分仅49.7%。
还对异步函数调用进行了改进。耗时较长的函数调用将不再阻塞会话流程——模型可以在等待结果的同时,保持流畅的对话。该功能已原生内置于gpt-realtime,开发者无需更新代码即可使用。
Realtime API的新功能
远程 MCP 服务器支持
您可以在实时API的会话配置中,通过传入远程MCP服务器的URL来启用MCP支持。连接后,API会自动处理相关的工具调用,无需手动进行集成。
该设置让您可以轻松地为智能体扩展新能力:只需将会话指向一个不同的MCP服务器,相应的工具便会立即可用。
// POST /v1/realtime/client_secrets{ "session": { "type": "realtime", "tools": [ { "type": "mcp", "server_label": "stripe", "server_url": "https://mcp.stripe.com", "authorization": "{access_token}", "require_approval": "never" } ] }}
图像输入
gpt-realtime现已支持图像输入。
可以将图片、照片、屏幕截图等视觉信息与音频或文本一同加入到实时API的会话中。
现在,模型可以将对话内容与用户所见的画面相结合,让用户可以提出“你看到了什么?”或“读一下这张截图里的文字”这类问题。
系统处理图像的方式并非实时视频流,而更像是在对话中插入一张图片。
应用程序可以决定在何时、与模型分享哪些图像。
通过这种方式,可以始终掌控模型看到的内容以及响应的时机。
{ "type":"conversation.item.create", "previous_item_id":null, "item":{ "type":"message", "role":"user", "content":[ { "type":"input_image", "image_url":"data:image/{format(example: png)};base64,{some_base64_image_bytes}" } ] }}
其他功能
此次更新还增加了多项功能,使Realtime API更易于集成,在生产使用中也更具灵活性。
会话发起协议 (SIP) 支持:通过实时API的原生支持,将应用连接到公共电话网络、PBX系统、桌面电话及其他 SIP端点。
这有点像马斯克此前推出的Ani打电话功能。
可重用提示词:可以像在Responses API中一样,保存并在不同的实时API会话中重用提示词——这些提示词可包含开发者消息、工具、变量以及用户/助手消息示例。
华人面孔+2
OpenAI的发布会必定会出现华人,这次发布会出现两张新面孔。
Beichen Li

Beichen Li目前是OpenAI的技术研究员。
研究方向是计算机图形学与机器学习的交叉领域,重点关注利用多模态大语言模型(MLLM)进行视觉程序合成。
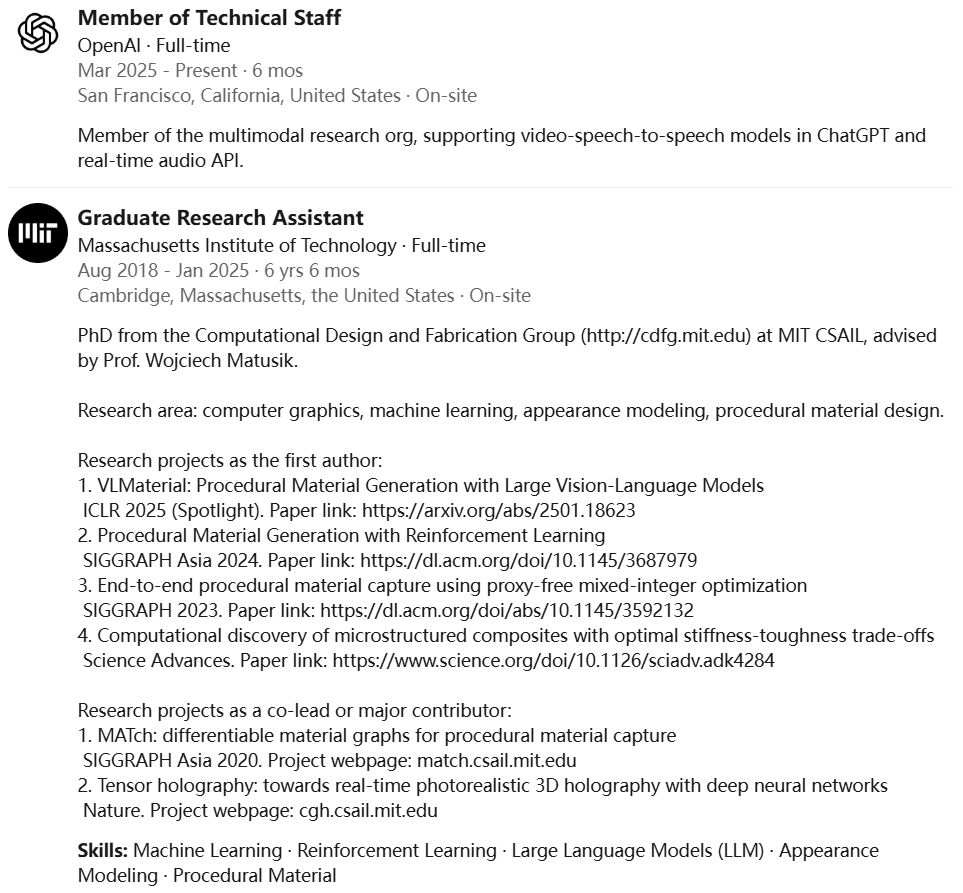
此前,他在MIT CSAIL获得计算机科学博士学位,师从Wojciech Matusik教授;在MIT获得电气工程与计算机科学硕士学位;在清华大学获得计算机科学与技术学士学位。

Liyu Chen

Liyu Chen目前是OpenAI的技术研究员。
此前,他在南加州大学获得博士学位,师从Haipeng Luo教授;在香港科技大学获得学士学位,毕业论文由Dit-Yan Yeung教授指导。