昨晚,终于等到了DeepSeek-R1-0528官宣。升级后的模型性能直逼o3和Gemini 2.5 Pro。如今,DeepSeek真正坐实了全球开源王者的称号,并成为了第二大AI实验室。
DeepSeek正式官宣R1已完成小版本升级,开启“深度思考”功能即可体验。在多项基准测试中,DeepSeek-R1-0528的数学、编程、通用逻辑性能,足以媲美最强o3和Gemini 2.5 Pro。而且,它还成为国内首屈一指的开源模型,全面超越Qwen3-235B。

除了性能刷新SOTA,此次R1的更新,还体现在了其他三方面:
前端代码生成能力增强 幻觉率降低45%-50%
支持JSON输出和函数调用

不仅如此,DeepSeek官方基于Qwen3-8B Base微调了更强版本——DeepSeek-R1-0528-Qwen3-8B。
这款8B模型在AIME 2024上,性能仅次于DeepSeek-R1-0528,甚至可与Qwen3-235B-thinking一较高下。

如今,DeepSeek不仅稳坐世界开源头把交椅,而且还成为了全球第二大AI实验室。

DeepSeek-R1迭代后推理更强,不过已有网友迫不及待催更R2了。

DeepSeek-R1数学编程更强了
HF模型卡中,DeepSeek具体公布了模型的更多的细节和性能对比。
DeepSeek-R1-0528是以DeepSeek V3 Base(2024年12月)为基座进行训练。

模型地址:https://huggingface.co/deepseek-ai/DeepSeek-R1-0528
在后训练阶段,R1投入了更多计算资源,并引入了算法优化机制,显著提升了模型的思维深度与推理能力。
如上所述,在数学、编程、通用逻辑等多项基准测试中,DeepSeek-R1展现出卓越的性能。

相较于上一代,0528版本在处理复杂推理任务方面取得了显著进步。比如,在AIME 2025测试中,R1准确率从70%提升到87.5%。

这一性能的提升,源于推理过程中思维深度的增强。
在AIME测试集中,DeepSeek-R1平均每个问题消耗12K token,而DeepSeek-R1-0528平均每个问题使用23K token。
在外部多语言Aider基准测试,结果显示,DeepSeek-R1-0528达到了与Claude 4 Opus相当的水平,Pass@2得分为70.7%。


幻觉率暴减50%
此前,有很多报道分析称,DeepSeek-R1虽比V3强,但幻觉率极高。
根据Vectara的测试,DeepSeek-R1幻觉率高达14.3%,比o3高出不少。

这一次,经过优化,与初代相比,DeepSeek-R1-0528的幻觉率降低了45%-50%。
尤其是,在改写润色、总结摘要、阅读理解等场景中,新模型能提供更加准确、可靠的结果。
而且,DeepSeek-R1还专门针对论文、小说、散文等问题,进行了进一步优化。
由此,它能够输出篇幅更长、结构内容更完整的长篇大作,更加贴近人类偏好的写作风格。

艾伦研究所Nathan Lambert通过实验发现,R1-0528在编译智能体基准上,表现非常稳健。

支持工具调用
值得一提的是,DeepSeek-R1-0528还可以支持工具调用。
比如,让它总结一篇文章,附上一个链接后,模型会主动调用爬虫插件获取网页内容,然后进行总结。
它在Tau-Bench的测评成绩为airline 53.5%/retail 63.9%,与o1-high性能相当,但与o3-High、Claude 4 Sonnet仍有一定的差距。

图源:DeepSeek
在前端代码生成、角色扮演等方面,DeepSeek-R1-0528能力得到了进一步提升。
比如,制作一张英文单词的复习卡片应用,短短几分钟,一个完整的APP就呈现了,包括复习卡片、搜索卡片、学习统计、创建卡片基本功能一应俱全。
而且,DeepSeek-R1函数调用支持增强,还为氛围编程(vibe coding)提供了更流畅的体验。

图源:DeepSeek
DeepSeek蒸馏版Qwen3-8B来了
在R1更新升级的同时,DeepSeek还蒸馏了DeepSeek-R1-0528的思维链,然后训练了Qwen3-8B Base,最后得到了DeepSeek-R1-0528-Qwen3-8B。
DeepSeek表示,DeepSeek-R1-0528的思维链对于学术界推理模型的研究和工业界针对小模型的开发都将具有重要意义。
DeepSeek-R1-0528-Qwen3-8B模型在数学测试AIME 2024中仅次于DeepSeek-R1-0528,超越Qwen3-8B(+10.0%),与Qwen3-235B相当。
这个结果还是挺夸张的,毕竟与Qwen3-235B相比,8B的模型在参数上相差将近30倍。
同时DeepSeek-R1-0528-Qwen3-8B的数学性能也强于最近的Phi-4 14B。

DeepSeek-R1-0528-Qwen3-8B等开源模型的AIME 2024对比结果
在数学性能上,DeepSeek-R1-0528-Qwen3-8B甚至超越了Gemini-2.5-Flash。
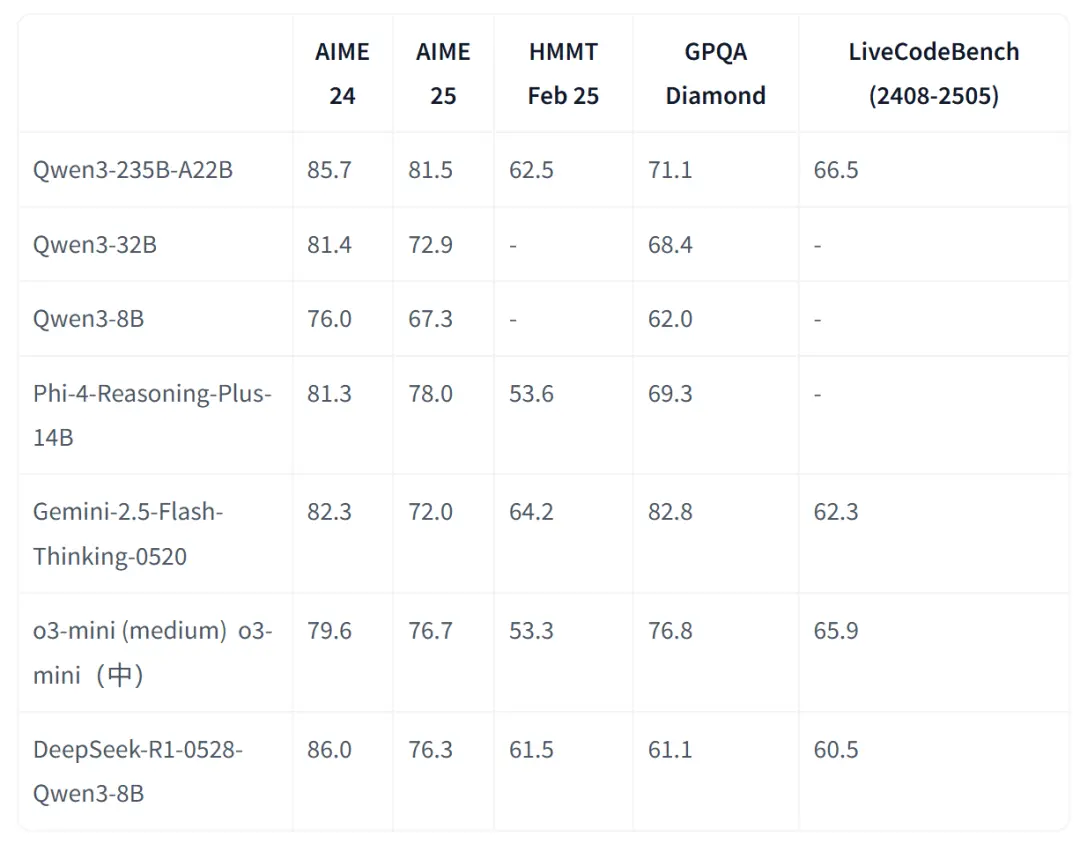
DeepSeek-R1-0528-Qwen3-8B等不同模型在多个基准测试中的性能
目前,这款8B蒸馏模型也已同步在Hugging Face上开源。

模型地址:https://huggingface.co/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
全球第二大AI实验室 荣光属于DeepSeek
就在DeepSeek R1更新后不久,独立AI分析网站Artificial Analysis发帖表示,DeepSeek的R1强势超越xAI、Meta和Anthropic。

这使得DeepSeek一跃成为全球第二大AI实验室,并无可争议的成为开源模型的领导者。
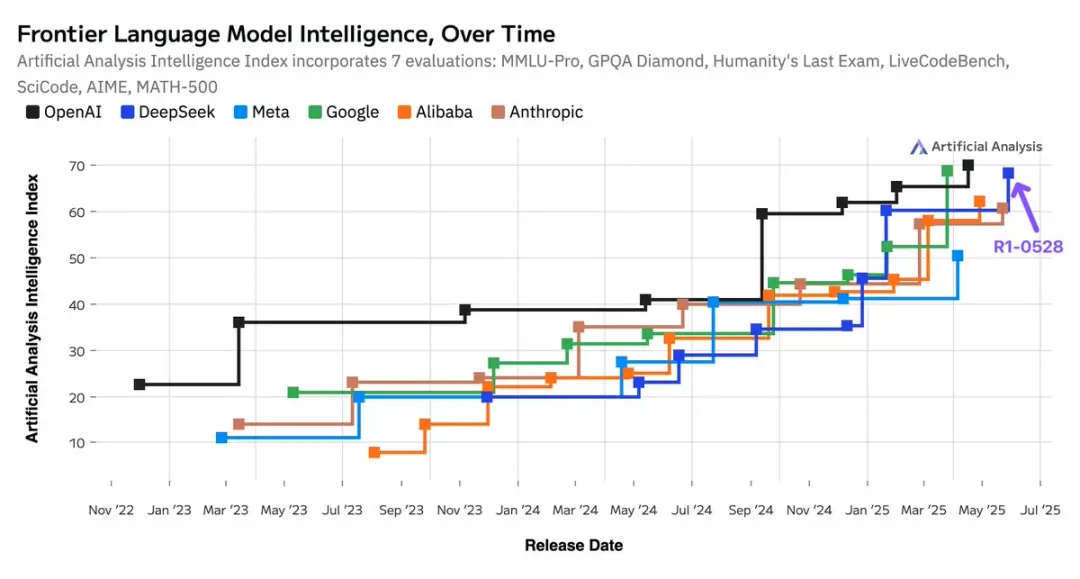
DeepSeek-R1-0528在智能指数中从60分跃升至68分,提升幅度与OpenAI的o1到o3(62分到70分)进步相当。
这使得DeepSeek R1的智能水平超过了xAI的Grok 3 mini(High)、NVIDIA的Llama Nemotron Ultra、Meta的Llama 4 Maverick、阿里的Qwen 3 253B,与Google的Gemini 2.5 Pro并驾齐驱。
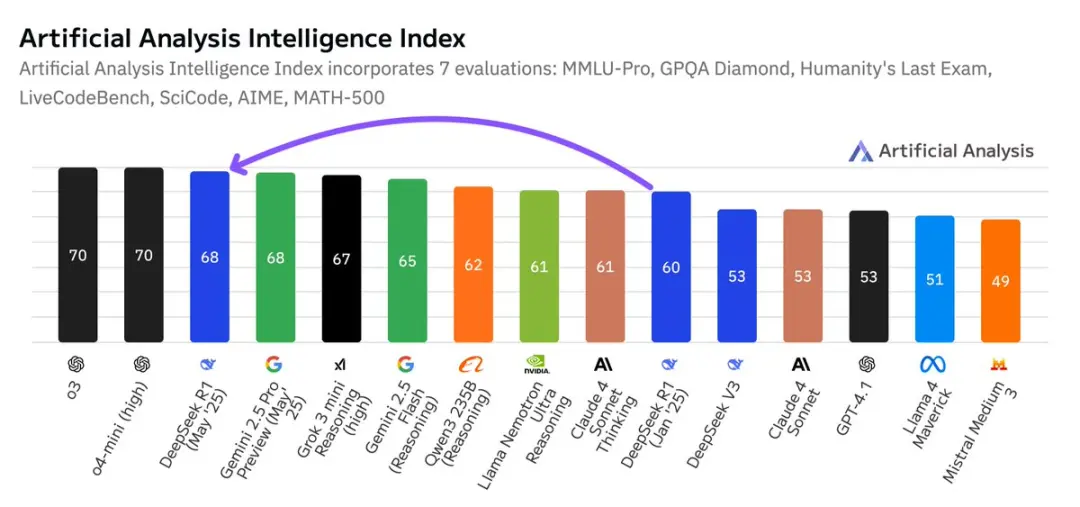
这些进步给AI领域带来了不少的启示:
开源与闭源模型差距缩小:DeepSeek今年1月的R1发布首次让开源模型登上第二位,这次的R1更新再次巩固了这一地位。
中国与美国AI并驾齐驱:来自中国AI实验室的模型几乎完全赶上了美国。目前,DeepSeek在人工智能分析智能指数中领先于美国AI实验室如Anthropic和Meta。
强化学习驱动进步:DeepSeek在相同架构和预训练基础上展示了显著的智能提升。这凸显了后训练的重要性,尤其是通过RL技术训练的推理模型。OpenAI披露o1到o3的RL计算规模扩大了10倍——DeepSeek证明了他们目前能跟上OpenAI的RL计算扩展。扩展RL比扩展预训练需要的计算资源更少,是实现智能提升的高效方式,更适合GPU较少的AI实验室。