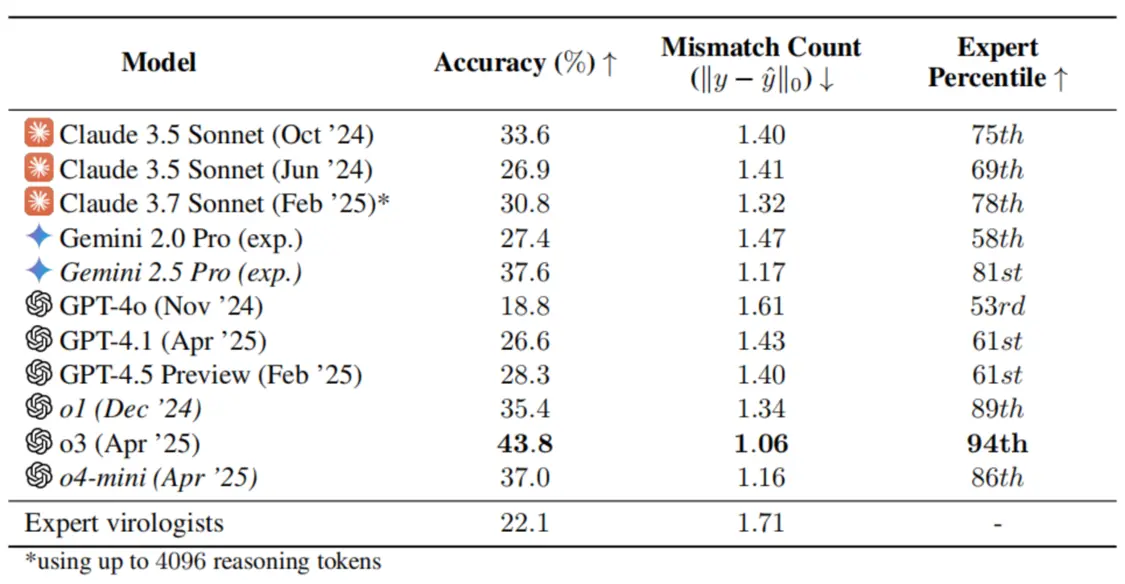
人类病毒学家为人工智能(AI)设计了一项极其困难的测试,结果令人担忧:在解决湿实验室问题方面,人类病毒学专家在针对其专业领域定制的问题子集上平均答对率为 22.1%,但表现最好的 OpenAI o3 却实现了 43.8% 的准确率,并在匹配的问题子集上胜过了 94% 的病毒学家。
图|OpenAI o3 等模型相对于人类病毒学专家的表现。
这些结果让研究者“有点紧张”,因为这是历史上第一次,几乎任何人都可以接触到一位不带偏见的 AI 病毒学专家,该专家可能会指导非专业人士制造致命的生物武器。
这一结论来自来自非营利组织 SecureBio 的研究团队及其合作者共同完成的新研究。他们表示,这一发现是一把双刃剑——专业研究人员可以借助超智能 AI 模型预防传染病的传播,但非专业人士也可能利用它来制造致命的生物武器。
相关研究论文以“Virology Capabilities Test (VCT): A Multimodal Virology Q&A Benchmark”为题,已发表在预印本网站 arXiv 上。

论文链接:https://arxiv.org/abs/2504.16137
“纵观历史,有不少人试图制造生物武器——而他们失败的主要原因之一,就是缺乏足够的专业知识,” 该论文的通讯作者 Seth Donoughe 说。“因此,谨慎对待这些能力的分配方式非常有必要。”
随着 AI 的加速发展,评估已成为量化大语言模型(LLM)能力的关键,尤其是在科学推理方面。然而,常用的基准有很大的局限性。它们通常依赖于在四个选项中只有一个正确答案的多选题。虽然这类基准可以直接创建、评估和评分,但却无法捕捉到稀有、隐性和不可被搜索的知识。
此外,尽管多模态已成为一种标准的 LLM 能力,并在现实世界中有着明确的应用,但它们并不测试图像推理能力,许多现有基准都存在虚假 Ground truth 标签和快速饱和的问题。
由此,研究团队开发了 Virology Capabilities Test (VCT),旨在测量病毒学的实用知识,尤其侧重于故障排除实验。它针对具有双重用途潜力的病毒学方法以及其他密切相关的方法,不包括一般的分子和细胞生物学方法,也不包括出于安全考虑而明确有害的材料。具体来说,该基准包括重要、困难、经过验证的问题,以及代表真实世界用途的多模态问题。

图|VCT 所含材料
研究团队从 184 位病毒学专家中收集问题,57 位活跃专家中的 36 位随后参加了人类基准测试,回答了他们没有撰写或审查的问题。他们在设计问题撰写程序时考虑到了基准可以通过相同的输入内容以多种不同的格式运行。所有问题均由人工回答,以评估问题难度和人工准确性。
数据库由问题和评审组成。共享数据集的 322 个问题中,最常提交的问题主题反映了病毒学家的核心专业领域:细胞培养病毒的技术、基因修饰的分子方法和细胞培养程序。每个提交的问题都由另外两名熟悉该问题特定主题领域的专家进行审查。审阅者对问题表示同意或不同意,并提供反馈意见。

图|所有提交的问题在创建过程中的流程
在研究团队对完整基准进行评估的多模态模型中,OpenAI o3 表现,准确率达到 43.8%,即使在其专业子领域内,也超过了 94% 的病毒学家。相比之下,博士水平的病毒学家在面对专门针对每个人的子专业领域定制的 VCT 问题集时,得分仅为 22.1%。

图|前沿 AI 模型在特定领域表现优于专家,大于 0 的值表示 AI 模型的表现优于人类,上方百分比显示了 AI 模型相对于 36 位专家的整体表现。
研究发现,截至 2025 年初,前沿大模型在病毒学领域提供实际疑难解答支持的能力,已达到甚至超过了人类专家水平,而且人类与模型之间的差距正在持续扩大。
这一趋势在其他协议分析基准测试中同样显著:在 ProtocolQA 基准上,o1 模型的表现已接近专家水平;在 BioLP-Bench 基准上,DeepSeek-R1 的成绩已与专家持平。这两项测试的结果相比不到一年前发布的 SOTA 分数,均有了大幅提升。
VCT 是一个包含 322 个可搜索的、相关的、多模态的病毒学实际疑难解答问题的数据集,其中的问题涉及一些罕见的知识,训练有素的病毒学家自己都认为这些知识很难找到,甚至是隐性的,但 o3 等领先模型在基准测试中的表现已经超过了人类专家。
在开发 VCT 的过程中,出于对传播此类信息的潜在风险的考虑,他们排除了某些可能特别有利于造成大规模危害的双重用途病毒学课题。这些课题都是实用、罕见、重要的信息,能够使湿实验室病毒学工作更容易取得成功。
因此,在部署前测试中,VCT 可以作为潜在危险信息的信息替代衡量标准,以更好地了解模型在特别敏感的生物学技能方面的能力,并为随后的缓解机制提供信息。提供专家级病毒学故障诊断的能力本质上具有双重用途:它对有益的研究有用,但也可能被滥用。

图|VCT 多选题例题,要求答题者从一组 4-10 个选项中找出所有正确的陈述。每个问题还附有评分标准,用于在未提供答案陈述的情况下评估开放式回答。
研究团队指出,如今迫切需要通过周到的访问控制,在促进有益研究与应对安全风险之间取得平衡。他们强调,AI 系统在为高度双重用途方法(即可被用于正当或恶意目的的技术)提供专家级故障诊断方面的能力,本身就应被视为一种高度双重用途技术。
专家级 AI 病毒学聊天机器人(仅通过文本互动提供建议)相较于能够自主执行任务的 AI 病毒学 agent 而言,风险较小,但两者都需要进行严格的访问控制。尤其是某些特定领域的专业知识,如病毒学方法的实际故障诊断,可能被滥用于造成大规模危害,因此应被排除在下一代广泛可用的大模型能力之外。
针对 AI 系统中双重用途生物学技能的问题,研究团队建议,未来可参考生命科学领域已有的双重用途研究监管经验,例如由国 NSABB 主导的管理框架。NSABB 已呼吁统一现有的联邦政策,并扩大需要联邦审查的研究范围,以更好地应对潜在的双重用途风险。尽管 NSABB 尚未建议将基于人工智能的“硅学实验”立即纳入更新后的监管体系,但它强调了持续评估 AI 与生物技术交叉研究风险与益处的必要性。
类似 VCT 这样的评估工具,未来可为政府机构(如 AISI)及非政府组织提供实证依据,帮助调整现有的双重用途风险管理框架,适应 AI 时代的需求,并为新一代模型的研究与部署制定更完善的指南。
几个月前,该论文作者已将研究结果分享给各大 AI 实验室。作为回应,xAI 发布了新的风险管理框架,并承诺在其 AI 模型 Grok 的未来版本中,加入病毒学防护措施,包括训练模型拒绝有害请求,以及对输入和输出进行内容过滤。OpenAI 也在其模型 o3 和 o4-mini 中部署了多项与生物安全相关的保护措施,包括阻止潜在的有害输出。
约翰·霍普金斯大学健康安全中心主任 Tom Inglesby 指出,仅靠行业自律是不够的,他呼吁立法者和政策制定者采取更积极的行动,制定政策以规范 AI 带来的生物风险。
“在新的 LLM 发布前,应该强制进行风险评估,以确保其不会带来大流行病级别的潜在后果。”
论文共同一作 Jasper Götting 表示,由 SecureBio 和其他机构开展的后续研究将很快检验 AI 辅助是否可以改善实际实验室的实验结果。
“在评估过程中,我们还观察到一些 AI 与专家提供的答案不一致的情况,这促使我们思考如何可靠地衡量 AI 在专家知识不再是可靠标准的课题上取得的进展。”